4.10 MySQL的高级进阶¶

一、增/删/改数据¶
1.1 新增数据¶
基本语法
insert into 表名[(字段列表)] values(值列表)[,(值列表)];
1.1.1 主键冲突¶
有时候会插入失败,因为主键冲突。这时可以选择:更新和替换
# 更新操作
insert into[(字段列表:包含主键)] values(值列表)[,(值列表)] on duplicate key update 主键字段 = 新值;
# 替换操作
replace into 表名 [(字段列表:包含主键)] values(值列表);
1.1.2 蠕虫复制¶
蠕虫复制: 从已有的数据中去获取数据,然后将数据又进行新增操作:
数据成倍的增加.
先复制表结构
create table 新表 like 源表;
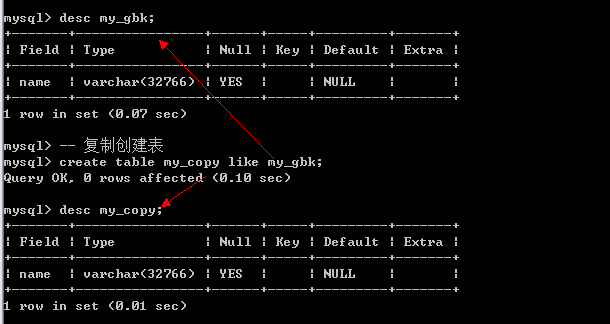
再插入表数据
insert into 新表 select 字段列表/* from 源表 where 条件;
蠕虫复制的意义1.2 更新/删除数据¶
update/delete 表名 set 字段 = 值 [where条件] [limit 更新数量];
二、查询数据¶
基本语法
Select 字段列表/* from 表名 [where条件];
完整语法
Select [select选项] 字段列表[字段别名]/* from 数据源 [where条件子句] [group by子句] [having子句] [order by子句] [limit 子句];
2.1 select选项¶
select选项有三种选项
*:选出全部字段,并且不做任何处理。等价于 all *(不用)
distinct *:对所有字段进行去重。
distinct 字段:对选定字段进行去重。
# 选出所有数据
select * from tb;
select all * from tb;
# 对所有字段进行去重操作(每个字段都相同才算重复)
select distinct * from tb;
# 对个别字段去重操作,下面两个语句等价
select distinct age, sex from tb;
select distinct(age),sex from tb;
# distinct必须放置最前面,这种写法是错误的
select sex,distinct age from tb;
2.2 字段别名¶
【语法】
select 字段名 [as] 别名 from 表名;
2.3 数据源¶
分为三种:单表数据源, 多表数据源, 查询语句
【单表数据源】
select * from 表;
【多表数据源】:查询结果为笛卡尔积(交叉连接),应避免。
select * from 表1,表2...;
【查询语句】:别名不可忽略,否则出错
Select * from (select 语句) as 表名;
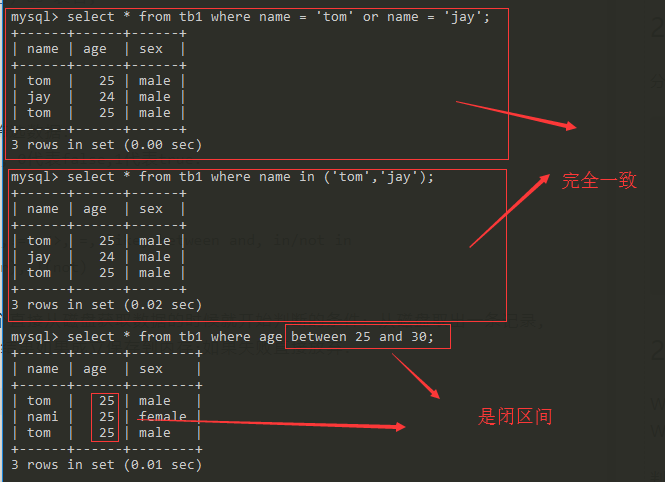
2.4 where子句¶
Where原理: where是唯一一个直接从磁盘获取数据的时候就开始判断的条件: 从磁盘取出一条记录, 开始进行where判断: 判断的结果如果成立保存到内存;如果失败直接放弃.
2.5 group by子句¶
group by【基本语法】
group by 字段名[,字段名];
分组会自动排序:默认升序
自定义排序
group by 字段名[,字段名] desc/asc;
Count(): 统计分组后的记录数:
每一组有多少记录,null不参与计数Max():统计每组中最大的值Min(): 统计最小值Avg(): 统计平均值Sum(): 统计和group_concat(字段)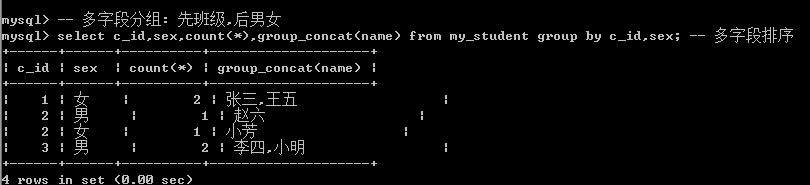
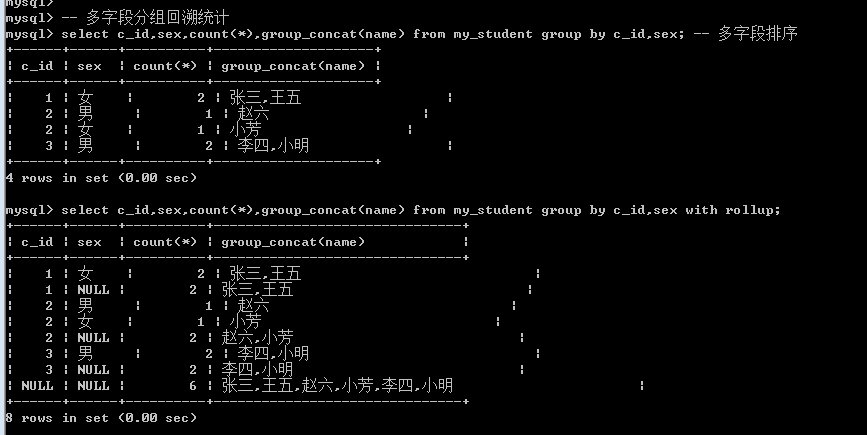
回溯统计(汇总统计)with rollup
任何一个分组后都会有一个小组, 最后都需要向上级分组进行汇报统计: 根据当前分组的字段. 这就是回溯统计: 回溯统计的时候会将分组字段置空.
如果只对一个字段分组汇总统计 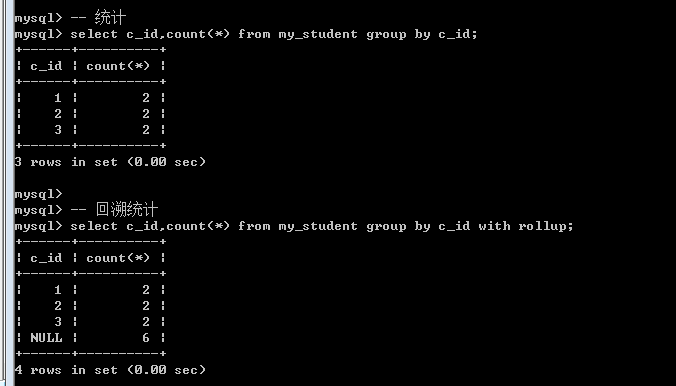 对两个字段进行分组统计汇总
对两个字段进行分组统计汇总
2.6 Having子句¶
Having子句: 与where子句一样: 进行条件判断的(只对分组进行判断,没有group by 就没有having).
where是针对磁盘数据进行判断: 进入到内存之后,会进行分组操作: 分组结果就需要having来处理.
Having能做where能做的几乎所有事情, 但是where却不能做having能做的很多事情.
比较 分组统计的结果或者说统计函数都只有having能够使用. 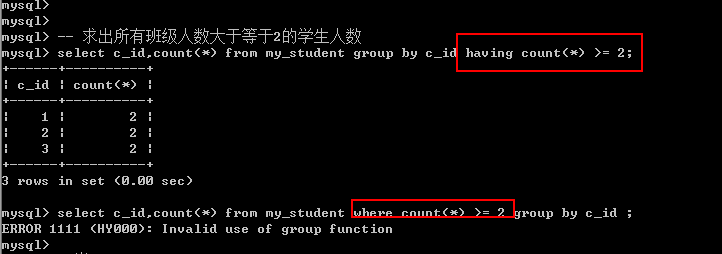
Having能够使用字段别名: where不能:
where是从磁盘取数据,而名字只可能是字段名:
别名是在字段进入到内存后才会产生. 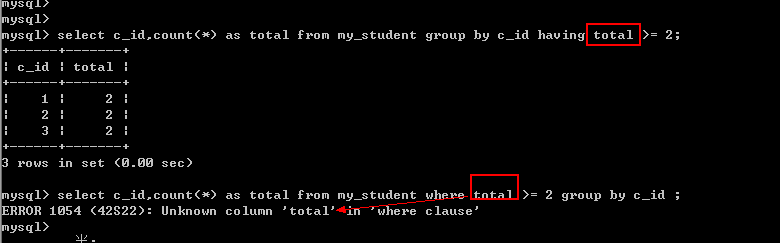
2.7 Order by子句¶
Order by: 排序, 根据某个字段进行升序或者降序排序, 依赖校对集.
【基本语法】
Order by 字段名 [asc|desc]; -- asc是升序(默认的),desc是降序
排序可以进行多字段排序: 先根据某个字段进行排序,
然后排序好的内部,再按照某个数据进行再次排序: 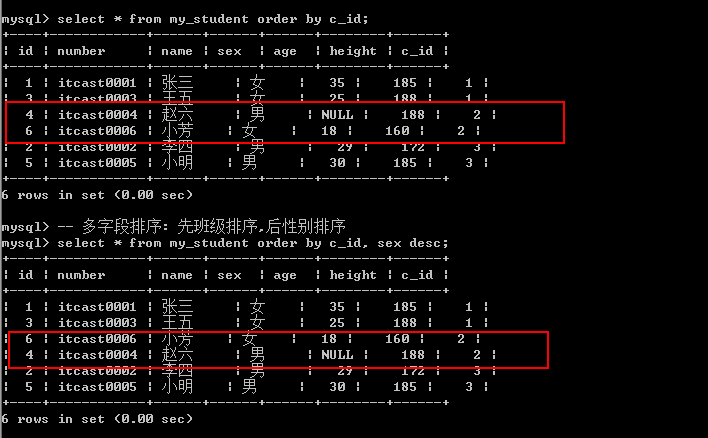
2.8 Limit子句¶
limit子句:限制返回数据的量。
有两种使用方式 方案1: 只用来限制长度(数据量): limit 数据量; 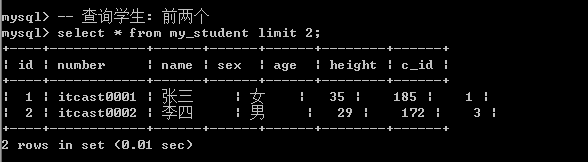 方案2: 限制起始位置,限制数量: limit 起始位置,长度;
方案2: 限制起始位置,限制数量: limit 起始位置,长度; 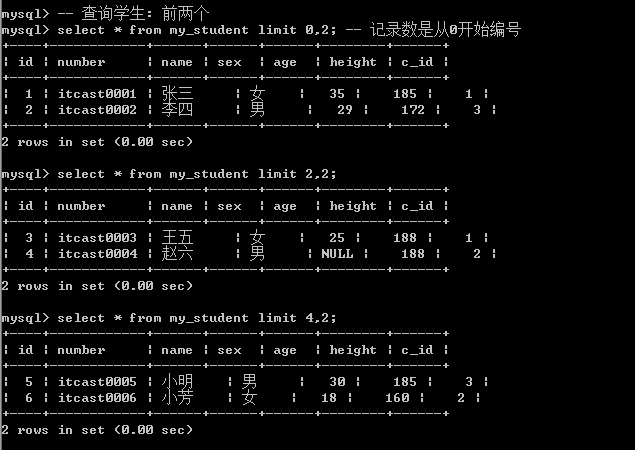
2.9 执行顺序【重要】¶

三、连接查询¶
连接查询: 将多张表(可以大于2张)进行记录的连接(按照某个指定的条件进行数据拼接): 最终结果是: 记录数有可能变化, 字段数一定会增加(至少两张表的合并)
连接查询的意义:
在用户查看数据的时候,需要显示的数据来自多张表(一定有外键连接)
连接查询 join, 使用方式: 左表 join 右表 左表: 在join关键字左边的表
右表: 在join关键字右边的表
连接查询分类 SQL中将连接查询分成四类:
内连接,外连接,自然连接和交叉连接
3.1 交叉连接¶
交叉连接:cross join 从一张表中循环取出每一条记录,
每条记录都去另外一张表进行匹配: 匹配一定保留(没有条件匹配),
而连接本身字段就会增加(保留),最终形成的结果叫做: 笛卡尔积.
【基本语法】
左表 cross join 右表; ===== from 左表,右表;
笛卡尔积没有意义: 应该尽量避免(交叉连接没用) 交叉连接存在的价值: 保证连接这种结构的完整性
3.2 内连接¶
内连接: [inner] join
从左表中取出每一条记录,去右表中与所有的记录进行匹配:
匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留.
【基本语法】
左表 [inner] join 右表 on 左表.字段 = 右表.字段;
on表示连接条件:,条件字段就是代表相同的业务含义(如my_student.c_id和my_class.id)
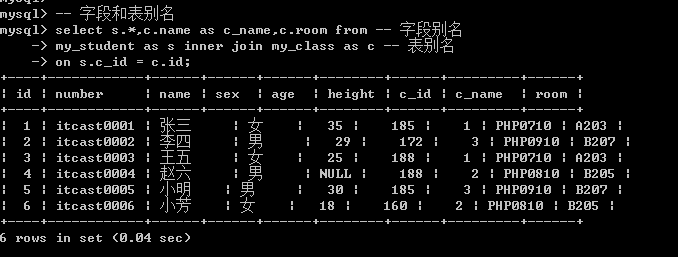 字段别名以及表别名的使用:
在查询数据的时候,不同表有同名字段,这个时候需要加上表名才能区分,
而表名太长, 通常可以使用别名.
字段别名以及表别名的使用:
在查询数据的时候,不同表有同名字段,这个时候需要加上表名才能区分,
而表名太长, 通常可以使用别名. 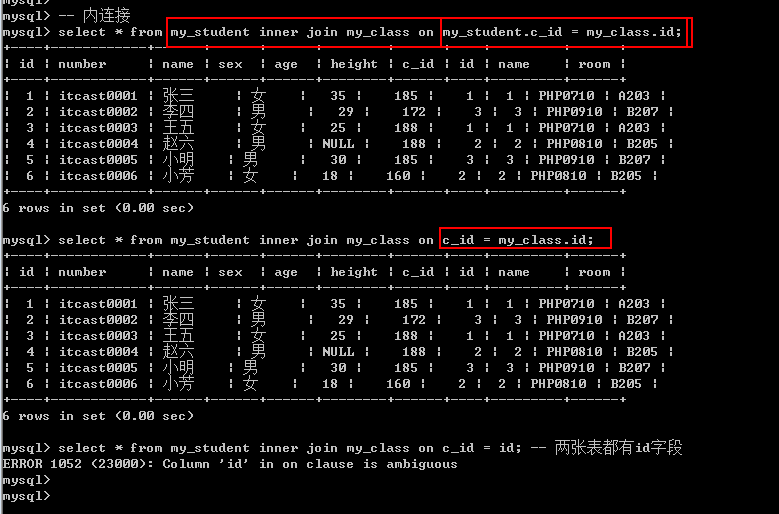
内连接还可以使用where代替on关键字(where没有on效率高) 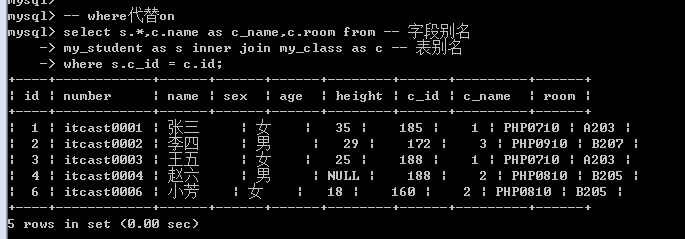
3.3 外连接¶
外连接: outer join 以某张表为主,取出里面的所有记录,
然后每条与另外一张表进行连接: 不管能不能匹配上条件,最终都会保留:
能比配,正常保留; 不能匹配,其他表的字段都置空NULL.
外连接分为两种: 是以某张表为主: 有主表
Left join: 左外连接(左连接), 以左表为主表 Right join:
右外连接(右连接), 以右表为主表
【基本语法】
左表 left/right join 右表 on 左表.字段 = 右表.字段;
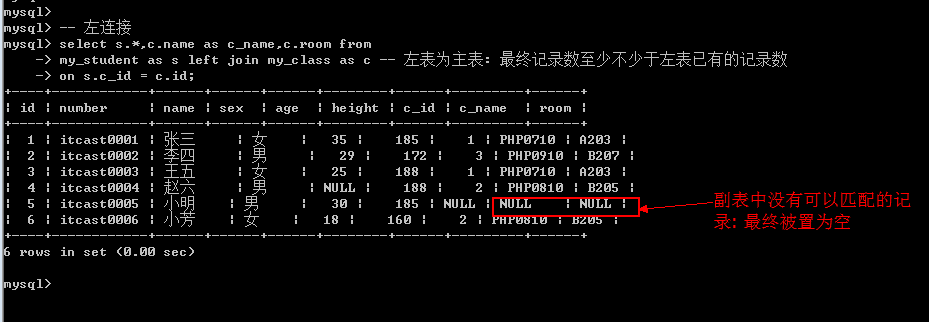 虽然左连接和右连接有主表差异, 但是显示的结果:
左表的数据在左边,右表数据在右边. 左连接和右连接可以互转.
虽然左连接和右连接有主表差异, 但是显示的结果:
左表的数据在左边,右表数据在右边. 左连接和右连接可以互转.
3.4 自然连接¶
自然连接: natural join 自然连接, 就是自动匹配连接条件:
系统以字段名字作为匹配模式(同名字段就作为条件,
多个同名字段都作为条件).
自然连接: 可以分为自然内连接和自然外连接.
【自然内连接】
左表 natural join 右表;
【自然外连接】
左表 natural left/right join 右表;
没有同名字段就不用使用了。 自然连接的内连接和外连接,除了上面的写法之外 还可以通过内连接和外连接来改造
【语法】
左表 left/right/inner join 右表 using(字段名); -- 使用同名字段作为连接条件: 自动合并条件
以上四种类型的连接,都可以进行多表连接
多表连接: A表 inner join B表 on 条件 left join C表 on条件 …
执行顺序: A表内连接B表,得到一个二维表, 左连接C表形成二维表…
四、联合查询¶
联合查询: 将多次查询(多条select语句), 在记录上进行拼接(字段不会增加)
多条select语句构成: 每一条select语句获取的字段数必须严格一致(但是字段类型无关)
4.1 基本语法¶
【基本语法】
Select 语句1
Union [union选项]
Select语句2...
Union选项: 与select选项一样有两个
All: 保留所有(不管重复)
Distinct: 去重(整个重复): 默认的
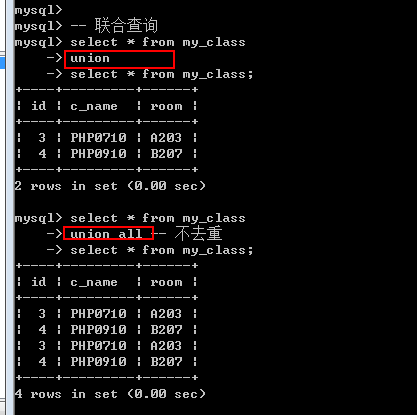 联合查询只要求字段数一样, 跟数据类型无关
联合查询只要求字段数一样, 跟数据类型无关 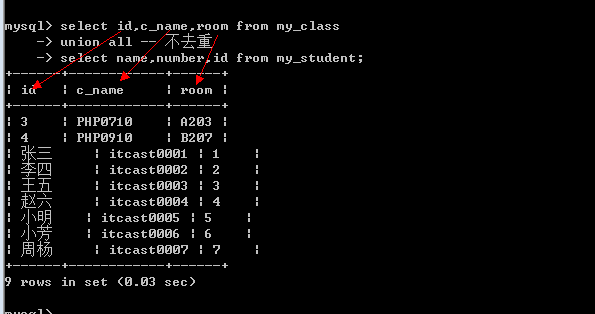
4.3 order by的使用¶
在联合查询中: order by不能直接使用,需要对查询语句使用括号才行 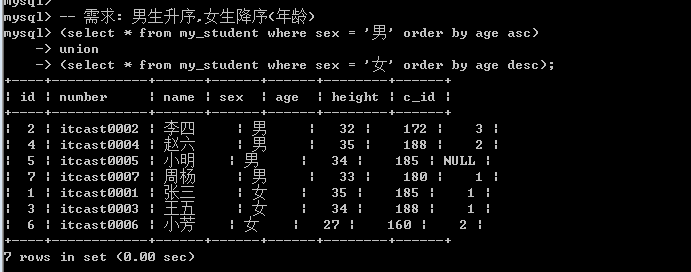 若要orderby生效: 必须搭配limit: limit使用限定的最大数即可.
若要orderby生效: 必须搭配limit: limit使用限定的最大数即可. 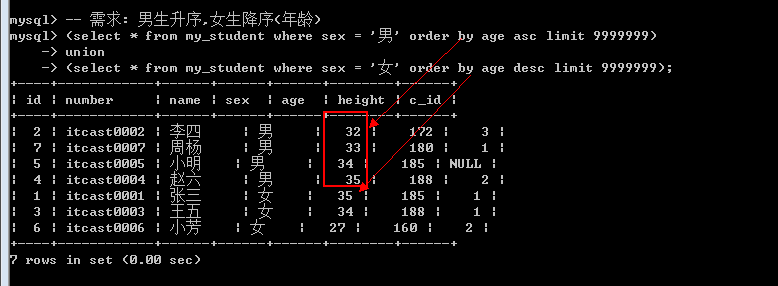
五、子查询¶
子查询: sub query
查询是在某个查询结果之上进行的.(一条select语句内部包含了另外一条select语句).
5.1 子查询分类¶
子查询有两种分类方式: 按位置分类、 按结果分类
【按位置分类】: 子查询(select语句)在外部查询(select语句)中出现的位置
From子查询: 子查询跟在from之后
Where子查询: 子查询出现where条件中
Exists子查询: 子查询出现在exists里面
【按结果分类】: 根据子查询得到的数据进行分类(理论上讲任何一个查询得到的结果都可以理解为二维表)
标量子查询: 子查询得到的结果是一行一列
列子查询: 子查询得到的结果是一列多行
行子查询: 子查询得到的结果是多列一行(多行多列)
-----上面几个出现的位置都是在where之后
表子查询: 子查询得到的结果是多行多列(出现的位置是在from之后)
5.2 标量子查询¶
标量子查询:返回的结果是一行一列,所以可以用 = ,!=
需求: 知道班级名字为PHP0710,想获取该班的所有学生.
1.确定数据源: 获取所有的学生
Select * from my_student where c_id = ?;
2.获取班级ID: 可以通过班级名字确定
Select id from my_class where c_name = ‘PHP0710’; -- id一定只有一个值(一行一列)

5.3 列子查询¶
列子查询:返回的一列多行,因此不能再用 = > < >= <= <>
这些比较标量结果的操作符
需求: 查询所有在读班级的学生(班级表中存在的班级)
1.确定数据源: 学生
Select * from my_student where c_id in (?);
2.确定有效班级的id: 所有班级id
Select id from my_class;
列子查询实现 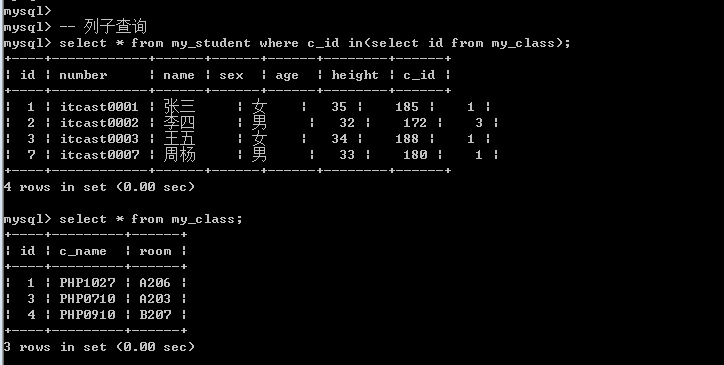
IN:在指定项内,同 IN(项1,项2,…)。 等价于 = ANY
NOT IN:不在列表里,等价于<> ALL
ANY:必须与比较操作符联合使用,表示与子查询返回的任何值比较为只要有一个为TRUE
,则返回TRUE 。
ALL:必须与比较操作符联合使用,表示与子查询返回的所有值比较都为TRUE
,才能返回TRUE。 SOME:ANY 的别名,较少使用。等价于ANY
5.4 行子查询¶
行子查询: 返回的结果可以是多行多列(一行多列)
需求: 要求查询整个学生中,年龄最大且身高是最高的学生. 1.确定数据源
Select * from my_student where age = ? And height = ?;
2.确定最大的年龄和最高的身高;
Select max(age),max(height) from my_student;
行子查询: 需要构造行元素: 行元素由多个字段构成 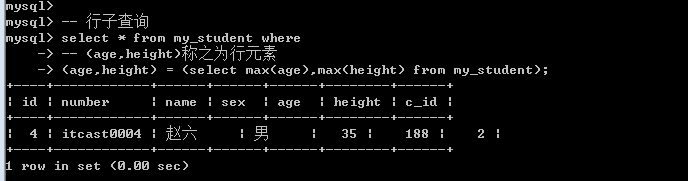
5.5表子查询¶
表子查询 子查询返回的结果是多行多列的二维表:
子查询返回的结果是当做二维表来使用
需求: 找出每一个班最高的一个学生.
1.确定数据源: 先将学生按照身高进行降序排序
Select * from my_student order by height desc;
2.从每个班选出第一个学生
Select * from my_student group by c_id; -- 每个班选出第一个学生
表子查询: from子查询: 得到的结果作为from的数据源 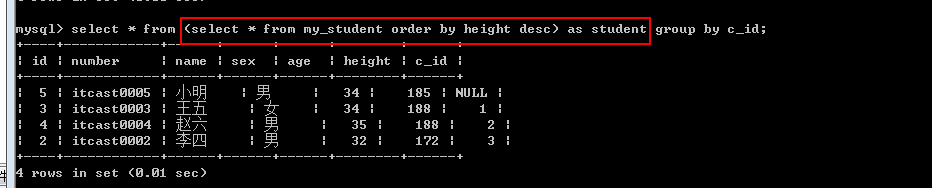
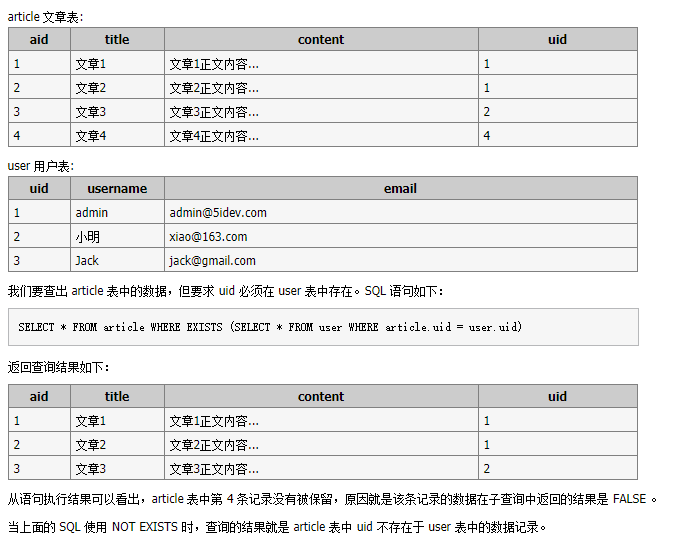
5.6 exits子查询¶
该语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定主查询的数据结果是否得以保留。
【语法】
SELECT ... FROM table WHERE EXISTS (subquery)
举个例子更好理解
六、系统查询¶
查询各库的使用量
select TABLE_SCHEMA, concat(truncate(sum(data_length)/1024/1024,2),' MB') as data_size,
concat(truncate(sum(index_length)/1024/1024,2),' MB') as index_size
from information_schema.tables
group by TABLE_SCHEMA
order by data_length desc;
查询一个库中各个表的使用量
SELECT CONCAT(table_schema,'.',table_name) AS 'Table Name',
CONCAT(ROUND(table_rows/1000000,4),'M') AS 'Number of Rows',
CONCAT(ROUND(data_length/(1024*1024*1024),4),'G') AS 'Data Size',
CONCAT(ROUND(index_length/(1024*1024*1024),4),'G') AS 'Index Size',
CONCAT(ROUND((data_length+index_length)/(1024*1024*1024),4),'G') AS 'Total'
FROM information_schema.TABLES
WHERE table_schema LIKE '%zabbix%' ORDER BY Total desc;
