4.3 30分钟教你搭建一个博客¶

10个优秀的程序员里,有9个人都有写博客的习惯。这是非常好的习惯,值得每个程序员,投入时间和精力去坚持做下去。
写博客的平台有很多,CSDN,博客园,51CTO,还有人会使用Hexo+GitHub,WordPress,比较会折腾的人还会自己使用Java,Python搭建,我就干过这样的事,不过每年还要支付域名和服务器,比较麻烦而且浪费钱。
以上博客我都有注册使用过,不过最终还是放弃。博客文章,比较零散,无法形成一个系统性的知识体系,不便索引。
为了使自己的文章能有一个比较完整的体系。经过一番探索之后,能满足我的基本要求的有如下两种:
GitHub Wiki,适合做知识整理,但排版一般,不方便查看。
GitBook,样式不好看,访问速度慢。
由于以上两种都有各自的不足的地方,所以我最后选择了一个完美的解决方案:Markdown+Pandoc+Sphinx+GitHub+ReadtheDocs 来管理我的文章。
Markdown:书写文档
Pandoc:格式转化
Sphinx:生成网页
GitHub:托管项目
ReadtheDocs:发布网页
1. 成品展示¶
以我的博客(pythontime.iswbm.com)为例,先给大家展示一下。
这是首页。显示了你所有的文章索引。 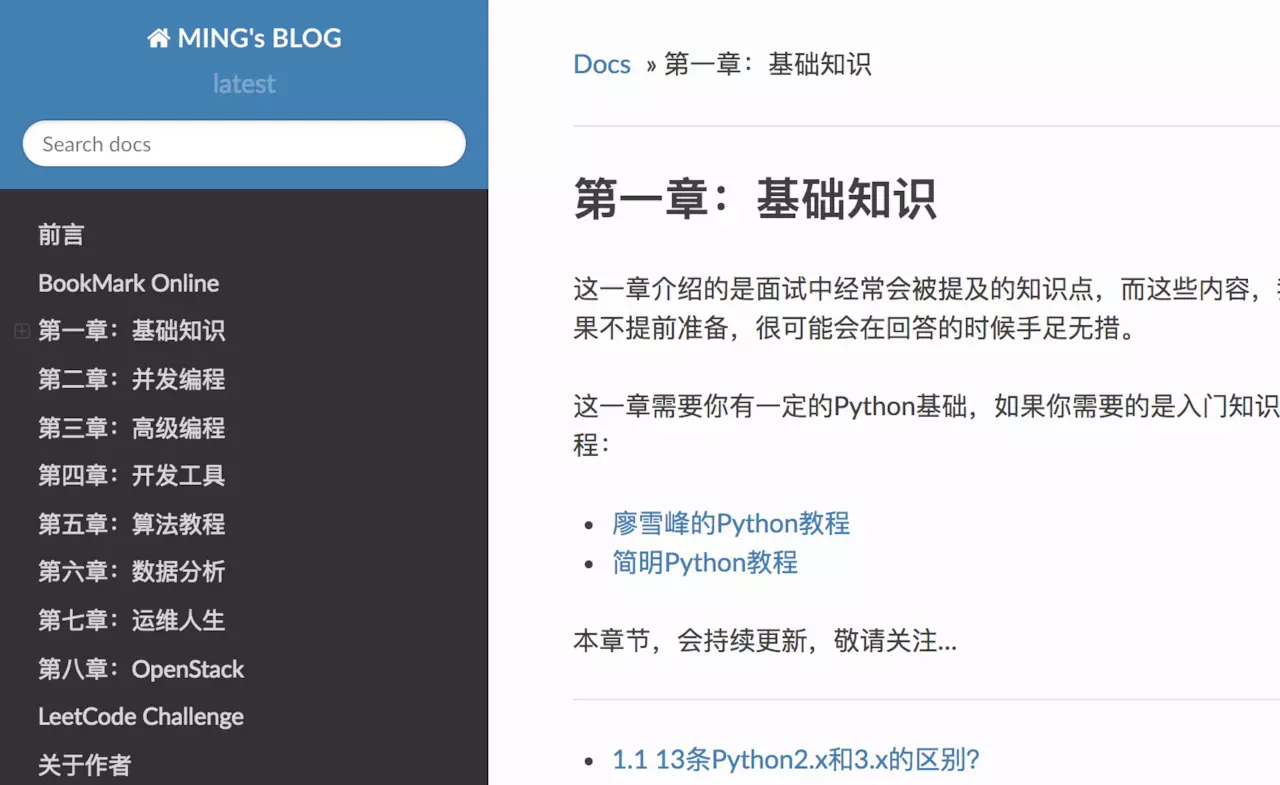
这是我的导航栏。是不是结构很清晰,很方便索引。 
点击文章后,还可以很方便查看标题,跳转。 
体验下搜索功能,速度很快。
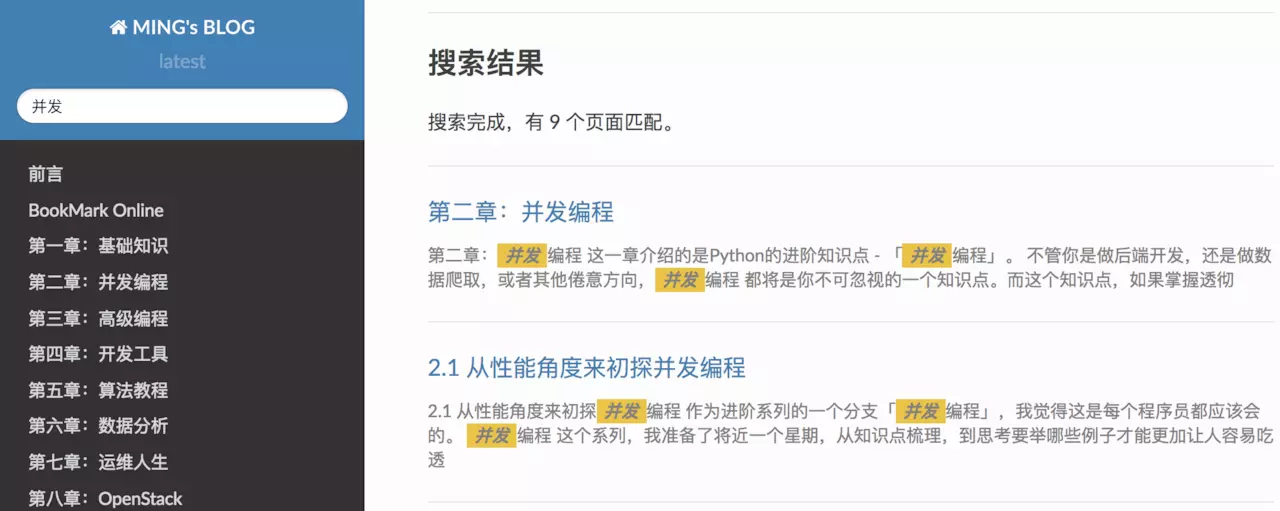
看完这些你是不是也很想拥有这样一个博客呢?
只要你认真往下看,30分钟搭建这样一个博客不在话下。
2. 安装Sphinx¶
安装之前,请确认下Python版本。我这里使用的是Python 2.7.14,其他版本请自行尝试噢,Python3.6好像有些坑,你需要踩一下。
安装Python工具包
$ pip install sphinx sphinx-autobuild sphinx_rtd_theme -i https://pypi.douban.com/simple/
初始化
# 先创建一个工程目录:F:\mkdocs
$ cd F:\mkdocs
$ sphinx-quickstart
执行这个命令sphinx-quickstart的时候,会让你输入配置。除了这几个个性化配置,其他的都可以按照默认的来。
> Project name: MING's BLOG
> Author name(s): MING
> Project release []: 1.0
> Project language [en]: zh_CN
完了后,就可以看见创建的工程文件。
F:\mkdocs
(mkdocs) λ ls -l
total 5
-rw-r--r-- 1 wangbm 1049089 610 Jun 23 16:57 Makefile
drwxr-xr-x 1 wangbm 1049089 0 Jun 23 16:57 build/
-rw-r--r-- 1 wangbm 1049089 817 Jun 23 16:57 make.bat
drwxr-xr-x 1 wangbm 1049089 0 Jun 23 16:57 source/
F:\mkdocs
(mkdocs) λ tree
卷 文档 的文件夹 PATH 列表
卷序列号为 0002-B4B9
F:.
├─build
└─source
├─_static
└─_templates
解释下这些文件/夹:
build:文件夹,当你执行make html的时候,生成的html静态文件都存放在这里。
source:文件夹:你的文档源文件全部应全部放在source根目录下。
Makefile:编译文件。完全不用管。
make.bat:bat脚本。你也不用管。
3. 配置及扩展¶
Sphinx 的配置文件是 source:raw-latex:conifg.py
由于修改的内容比较多而杂,为了使这个搭建过程,更加顺畅。
小明已经给你精心准备了一份配置文件。你只要关注我的公众号「Python编程时光」,后台直接回复
「Sphinx」即可获取。
关于配置文件,我做了哪些事:
配置主题
支持LaTeX
支持中文检索
以上配置文件,需要搭配扩展模块才能使用。扩展模块同样我也给你准备好了,在你回复「Sphinx」后,获取压缩包后,里面有个 exts 文件夹。你只要将这个文件夹原封不动的放置在与source的同级目录下即可。
由于扩展模块会用到一些第三方依赖包,需要你去包装它。requirements.txt 同样我也给你准备好了,在压缩包里有。
你只要执行这个命令,即可安装。
pip install -r requirements.txt -i https://pypi.douban.com/simple/
4. 撰写文章¶
万事俱备,接下来要写文档了。
在source目录下,新增文件 how_to_be_a_rich_man.rst(至于什么是rst格式呢,请自行搜索引擎噢)
文件内容如下
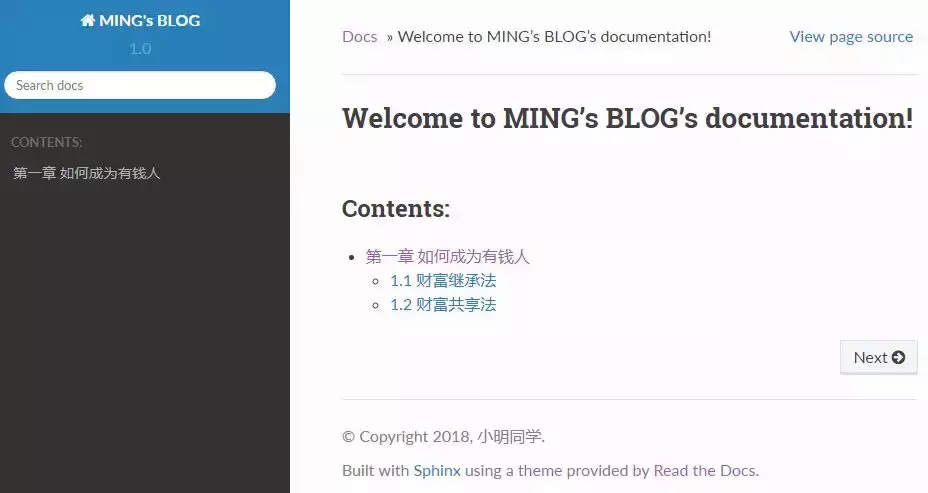
第一章 如何成为有钱人
======================
1.1 财富继承法
---------------------
有个有钱的老爸。
1.2 财富共享法
---------------------
有个有钱的老婆。
写好文档后,千万记得要把这个文档写进,目录排版里面。
排版配置文件是 source:raw-latex:index.rst,千万要注意中间的空行不可忽略。
.. toctree::
:maxdepth: 2
:caption: Contents:
how_to_be_a_rich_man
然后删除这几行吧,没啥用。
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
然后执行make html 生成html静态文件。
F:\mkdocs
(mkdocs) λ make html
Running Sphinx v1.7.4
loading translations [zh_CN]... done
loading pickled environment... done
building [mo]: targets for 0 po files that are out of date
building [html]: targets for 2 source files that are out of date
updating environment: [extensions changed] 2 added, 0 changed, 0 removed
reading sources... [100%] index
looking for now-outdated files... none found
pickling environment... done
checking consistency... done
preparing documents... done
writing output... [100%] index
generating indices... genindex
writing additional pages... search
copying static files... done
copying extra files... done
dumping search index in English (code: en) ... done
dumping object inventory... done
build succeeded.
The HTML pages are in build\html.
执行完了后,你可以发现原先的build,不再是空文件夹了。
真棒,已经完成了一半了。点击 我们刚写的 暴富指南。 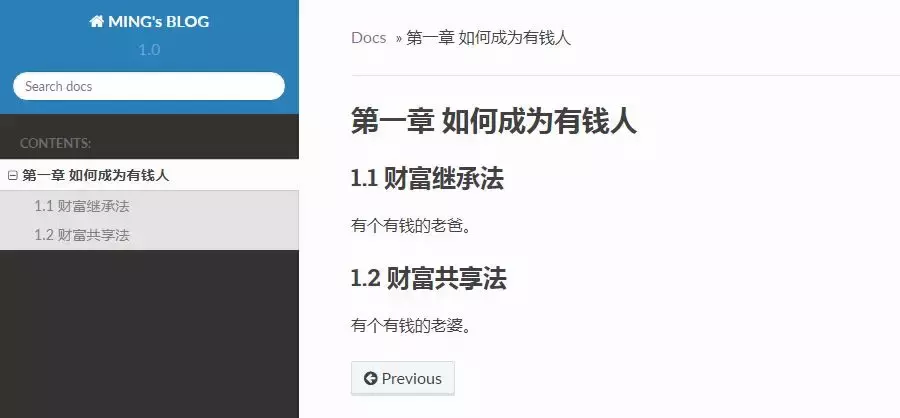
5. 托管项目¶
看到网页的那一刻是不是相当激动。
不过别激动,这只是本地的,我们需要将其发布在线上。
这里我将工程文件,托管在GitHub上,然后由Read the Docs发布。
在托管之前呢,我们需要准备工作。在mkdocs根目录下,添加文件.gitignore(聪明的你,肯定知道这是什么),内容如下
build/
.idea/
*.pyc
接下来,在你的GitHub上新建一个仓库。然后把mkdocs这个目录下的所有文件都提交上去。步骤很简单,这里就不细讲了。
6. 发布上线¶
托管完成后,我们要发布它,让别人也可以使用公网访问。
你需要先去 Read the Docs 注册下帐号。
关联一下GitHub 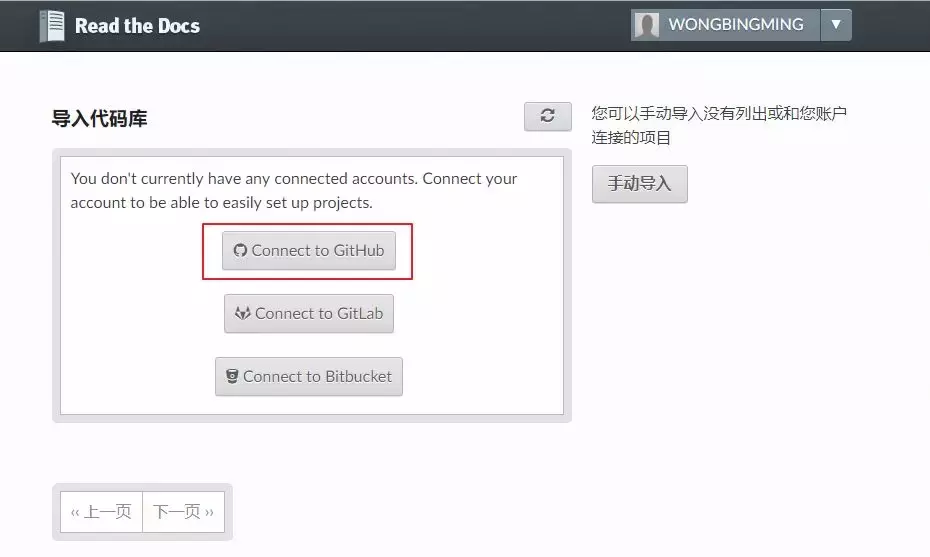
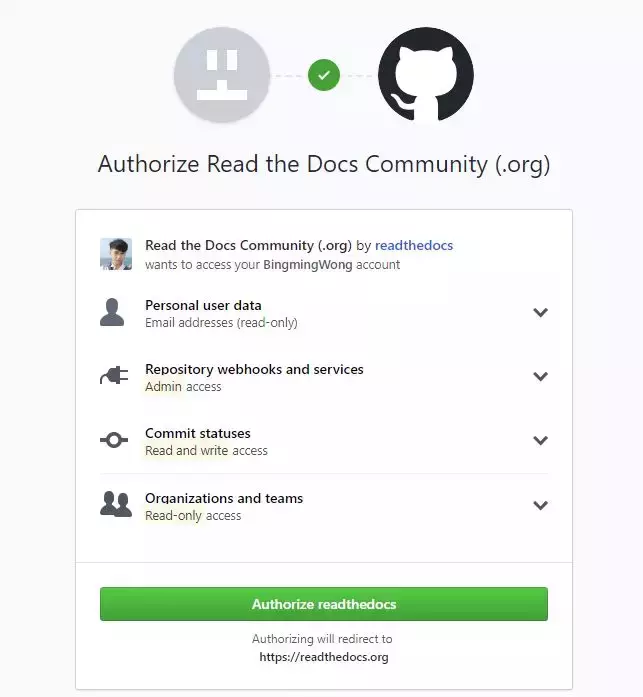
导入代码库。填好与你对应的信息。 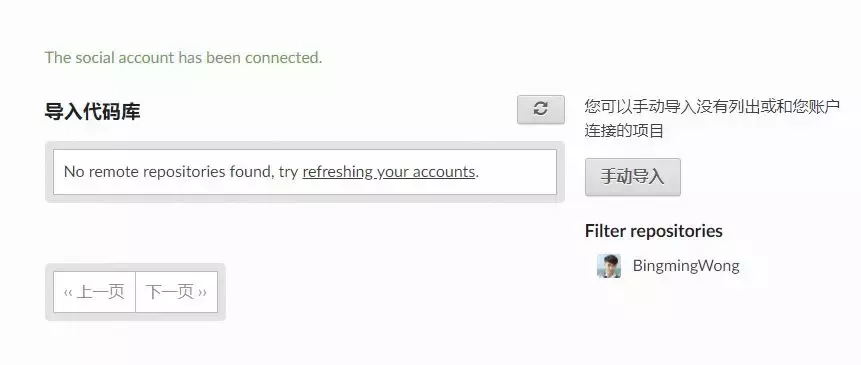
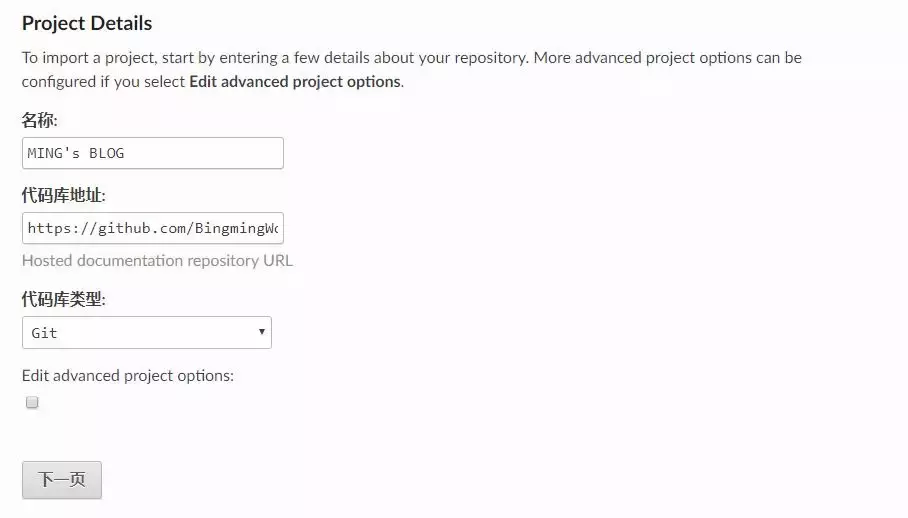
构建网页后。右下方,你可以看见你的在线地址。
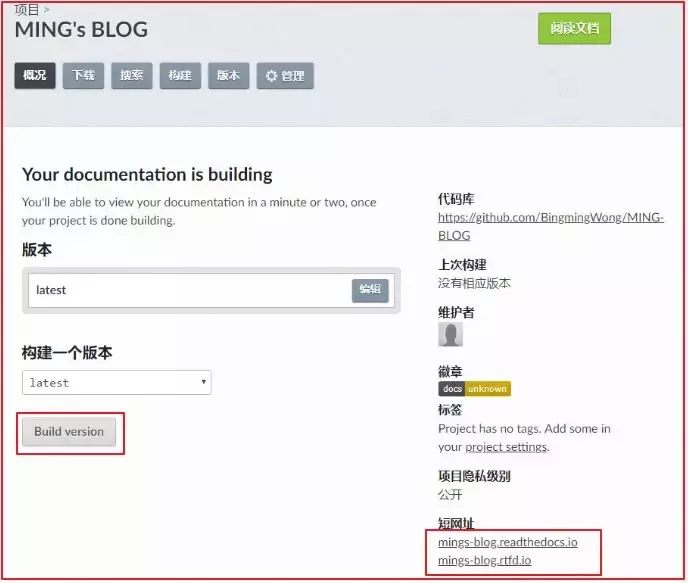
这里要提醒一下的是,Sphinx的文档格式,默认是 rst 格式,如果你习惯了使用Markdown来写文章,可以使用 Pandoc 这个神器转换一下。
这里给出格式转换命令。
pandoc -V mainfont="SimSun" -f markdown -t rst hello.md -o hello.rst
或者你也可以在 Sphinx 上添加支持 Markdown 渲染的扩展模块。这需要你自己去折腾了。
到这里,属于你的个人博客就搭建好了,快去试一下吧。
最后,整个项目的源码和模块包我都放在公众号(Python编程时光)后台,请关注后,回复「Sphinx」领取。
7. 自定义插件¶
之前有不少同学看过我的个人博客(http://pythontime.iswbm.com),也根据我写的搭建教程,完成了自己的个人站点。
使用这个方法搭建的站点,一直有一个痛点,就是无法自定义页面,自由度非常的低(和 WordPress 真的是没法比,因为这两种产品定位本身就不一样。)
这就导致我一直不知道到底有没有人访问我的网站? 他们都是从哪来访问的,Google 还是 百度? 我一直在我的博客上贴上我的公众号二维码,可到底因此关注我的人有多少呢?
因此我一直希望能找到一个能够得知网站访问数据、并且能将博客上的访客引导到公众号上来的方法。
终于在昨天我找到了,并花了两天的时间成功上线。
方法就是引入两个 JavaSript 插件实现。
7.1 第一个插件:导流工具¶
作用:用于将自己博客上流量引导到自己的公众号上。
具体是思路是:
游客无法阅读博客的全部内容,因为会有一半的内容会被隐藏,就像这样。

如想要浏览完整内容,需要点击 “阅读全文” 进行解锁:
用微信扫描二维码关注我的个人公众号;
发送
more,获取到的验证码;在如下文本框中输入验证码。
这样就可以永久解锁本博客的所有干货文章。 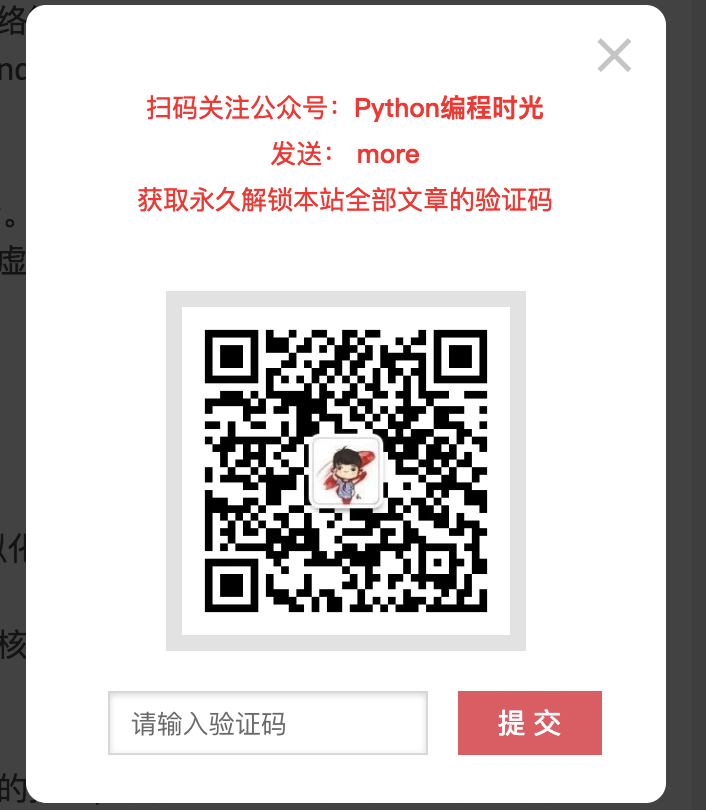
思路有了,那么如何实现呢?
以上功能其实已经有人已经做出来并可以提供免费使用。
你可以在 https://openwrite.cn/
注册一个帐号,然后在里面你可以看到一个导流工具,填写你的公众号及引流的相关信息后,就初始化成功,获得一串js代码。
接下来,你要做的就是将这串js接入你的博客页面中。
由于我去年搭建这个博客时使用的 Sphinx 的版本是 1.7 ,这个版本是不支持自定义css/js 文件的。
因此,你要使用引入这段js代码,需要将你的 Sphinx 升级到 1.8+,我使用的是最新版本的 2.1 ,这个版本只支持 Python 3.5+。
因此在使用之前,我得先将环境的切换至 Python 3.5+。
virtualenv -p /usr/bin/python3.6 myblog
然后重新安装 Sphinx 及相关包。
pip install Sphinx sphinx-rtd-theme -i https://pypi.douban.com/simple
问题一
虽然现在我们的 Sphinx 已经支持自定义js了(方法是将一个js文件以引用的方式放在 header 标签里)
但是 OpenWrite 要实现 阅读全文 的效果,这个js必须放在 HTML
的尾部,意思是要等页面加载完成后才能起作用。
这下就尴尬了。Sphinx 会将 js 放在 HTML 顶部,而要实现 阅读全文
的效果,js
需要放在底部。由于框架是固定的,我们无法对其进行定制修改。那还有什么方法可以补救呢?
我的方案是:在 js 中加入逻辑,当页面加载完成后再运行。
问题二
若要 readmore.js 起作用,需要在你的文章的正文div中加入一个id=‘container’, 而这个 Sphinx 默认是不会生成的。
这样的话,这个动态添加 id 属性的工作也只能交由 readmore.js 来做了。
问题三
由 Sphinx 生成的的所有页面都会加引入这个 js
插件,这就导致所有的页面(包括首页,索引页)都会有 阅读全文
的限制。这明显是不合理的。
为了解决这个问题,我想的是在 readmore.js 中,根据 url 进行判断,只有文章页面才有限制,而其他的页面则不受限制。
总结一下,这个 readmore.js 会做三件事:
判断页面是否加载完成,加载完成后才执行;
给 class 为
rst-content的 div 加一个 id 属性:container;根据网页地址判断是否文章页面,是则执行,否则不执行;
如果你不想自己写这个 js 文件,可以在我的公众号后台,添加我微信,备注 “导流”,直接获取我写好的js文件,你对应修改即可使用。
获取到的 js 文件需要放在固定的路径下: source/_static/js/
(如果没有此路径就手动创建),然后修改 conf.py
html_static_path = ['_static']
html_js_files = [
'js/readmore.js',
]
按理说,这样就已经大功告成了。
但是别忘了,我们是用 readthedocs 生成我们的博客页面的。
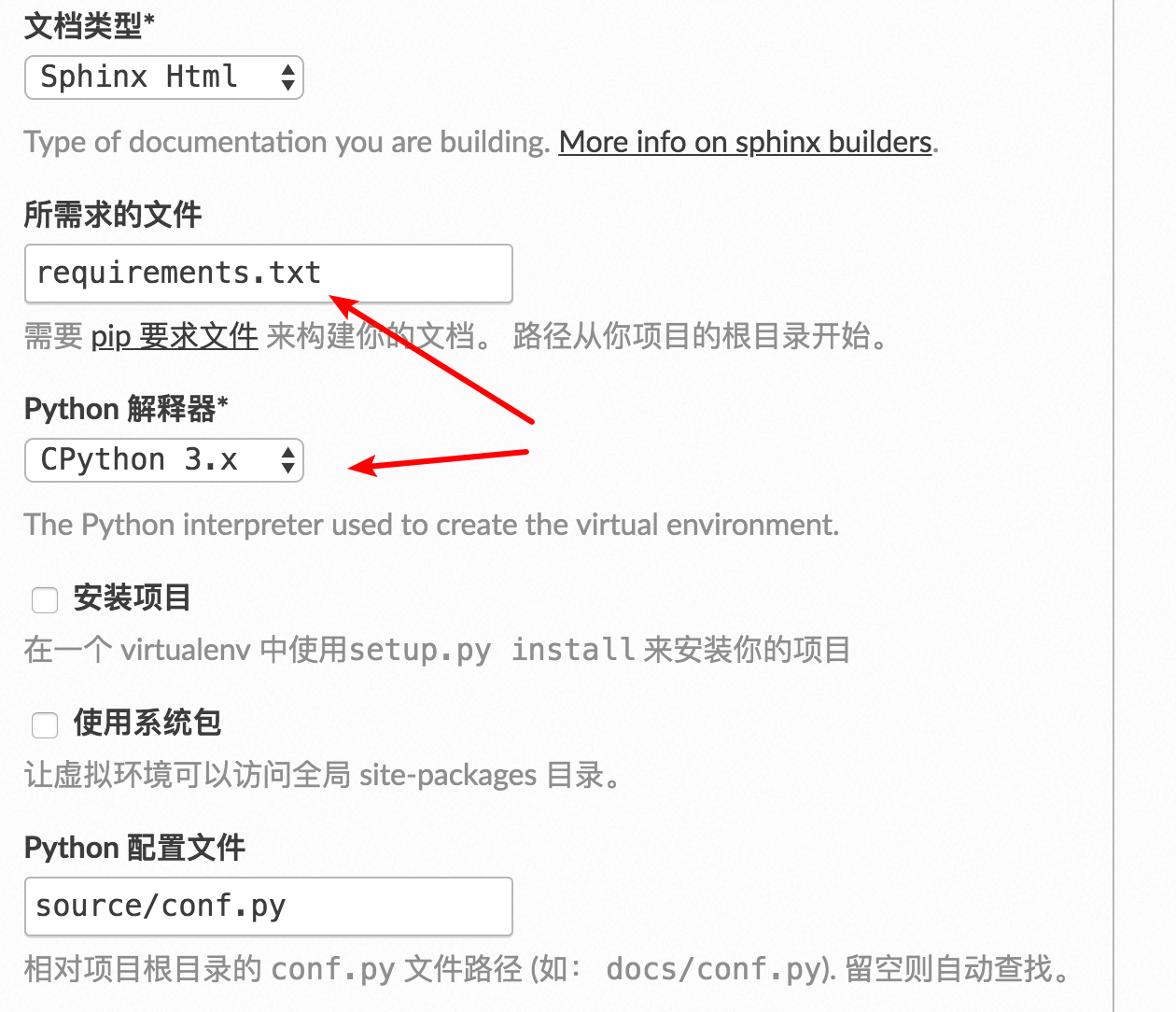
对此,我们同样也要在 readthedocs 进行相关的配置
改 CPython 2.x 为 CPython 3.x
指定我们的本地生成的 requirements.txt(使用 pip freeze >requirements.txt)
同时你如果之前是看过我写的教程,使用过我的中文检索插件,那你要注意了。
此前这个插件是基于 Python 2.x 写的,现在我们切换成 Sphinx 项目切换成 Python 3.x ,所以这里的代码也要对应修改。
改动也不大,只要把 exts/smallseg.py 这个文件里的 decode
相关的代码全部去掉即可。
一切按照上面的步骤全部设置完成后,提交Github后,再次从 readthedocs 构建就可以看到效果了。
3.2 第二个插件:百度统计¶
作用:用于收集个人网站的访问数据。
有了上面的经验,现在我们知道如何在页面中插件自定义 js 代码。
那我就想有没有那种可以通过引入 js 插件来收集网站的访问数据呢?
这种工具应该不少,而我使用的是百度家的产品 - 百度统计 。
它可以帮我们收集网站访问数据,提供流量趋势、来源分析、转化跟踪、页面热力图、访问流等多种统计分析服务。
那怎么使用呢?
首先使用你的百度帐号登陆 百度统计。
然后在网站列表新增一个你的网站,我的信息如下:
填写完成,就可以获取一段属于你的网站的专属 js 代码(下面第一步)。
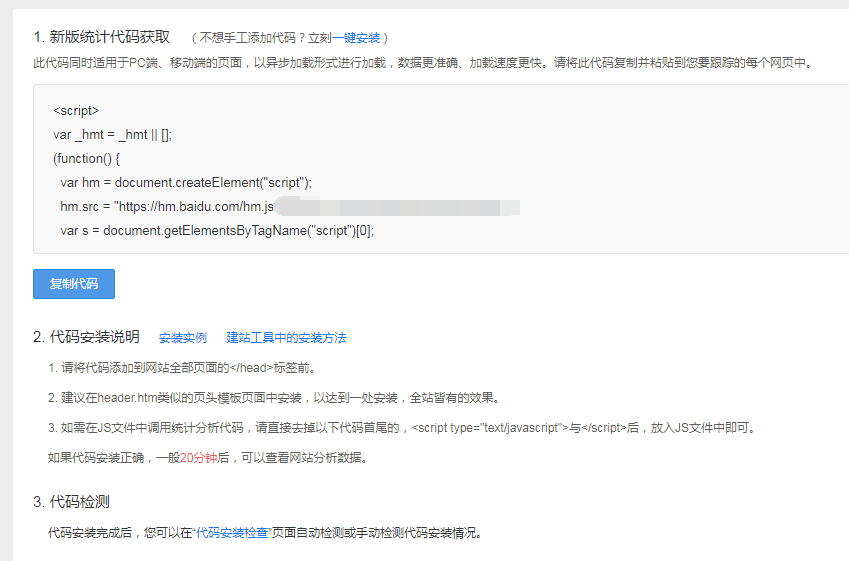
第二步内容,是教你如何安装这段 js 代码。
将这段代码内容写入一个单独的 js 文件:baidutongji.js
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?xxxxxxxx";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
并修改 conf.py 后,提交至你的 Github。
html_js_files = [
'js/readmore.js',
'js/baidutongji.js'
]
一切完成后,就可以去 readthedocs 重建构建。
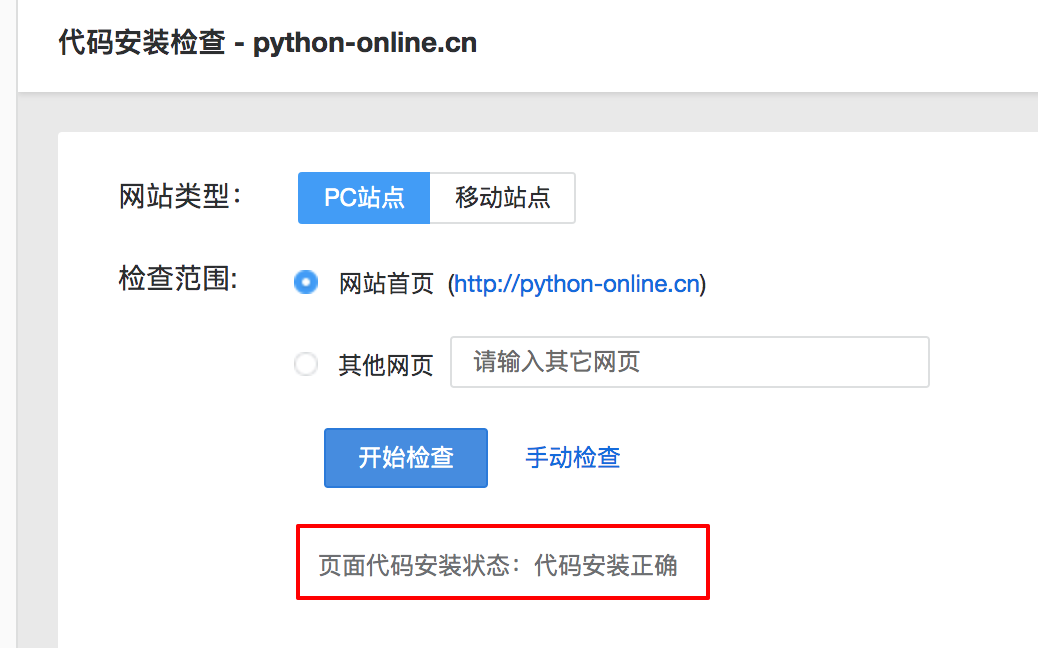
构建完成后,去执行第三步,代码安装检查。像我下面这样,就是安装完成了。
这个插件安装完成后,如果你的网站有流量,可以过个一个小时,点击一下查看报告查看你网站的详细访问数据。
数据真的非常全面,你可以知道,访客都是从哪里访问(直接访问,Google等),每篇文章的点击量(你就知道哪篇是爆款?),每天有多少老访问客,多少新访客等等,更多维度的数据你可以自己去体验一下。
###3.3 第三个插件:评论系统
先到这个网站去注册一个 disqus 帐号,我使用了 gmail 帐号进行注册
然后根据指引填写好资料
选择基础版