5.3 哈希算法:安全方面的算法应用¶

昨天准备登陆某网站的时候,在尝试了几次常用密码失败后,我点击了“忘记密码”,娴熟地填入手机号码,随即就收到了一条来自陌生号码的短信,里面包含着一个六个数字串,将这个数字串填入网站提供的输入框,就进入了密码重置流程。
这里有一点细节,值得我们注意,为什么我忘记了密码,你不直接把这个密码返回给我?而是给我一个不相关的口令来重置密码?
前段时间,华住(某大型连锁酒店)由于内部程序员失误,将数据库密码公开于Github上,让人拿走了数亿用户的开户记录和他们的登陆信息(包括密码)。试想一下,如果这些密码用明文存储的话,那不法分子会用这些用户的邮箱和密码去登陆你的各种社交网站,甚至各种金融帐户,如此数量级下(上亿),对于互联网安全将是一场巨大的浩劫。
如此看来,服务器是不会明文存储你的用户密码的。这也就能解释,为什么不干脆直接将原密码返回给你了。
那么问题来了,在数据库存储的到底是什么?它应该是被某种算法加密过的密文,并且无法进行反向破解,保证了被黑客拿到了也能保证数据的相对安全。
5.3.1 哈希算法¶
哈希(Hash)算法,由于其不可反向破解的特性被广泛用于私密信息的保护。
这里要事先说明一下,哈希(Hash) 和 加密(Encrypt) 的区别,不少人会混淆起来:
哈希:将目标文本转换成具有相同长度的、不可逆的字符串,也叫消息摘要,是一对多的映射关系(即多个明文可能对应同一个哈希值)。
加密:将目标文本转换成具有不同长度的、可逆的密文,是一对一的映射关系(即一个密文只能对应一个明文)
哈希算法是一个比较泛的概念,他的具体实现有许多种,大家所熟知的有 MD5,SHA256等。
现在拿 MD5来举例,MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),但是人类实在看不惯二进制,所以128位的二进制通常会表示成32位的十六进制(由0-9,a-f组成),他们是等价的。
说了那么多,这个散列值到底长啥样呢。
在Python中
import hashlib
m1 = hashlib.md5()
m1.update("hello")
print(m1.hexdigest())
# 5d41402abc4b2a76b9719d911017c592
用shell就更简单了
echo -n hello | md5sum
# 5d41402abc4b2a76b9719d911017c592 -
由于哈希算法是一对多的映射,所以不同的输入是有可能得到了同一个哈希值,这时候就发生了“哈希碰撞”(collision)。

img¶
案例一¶
一个很典型的应用,很多网络服务会使用哈希函数,产生一个 token,标识用户的身份和权限。
如果两个不同的用户,得到了同样的 token,就发生了哈希碰撞。服务器将把这两个用户视为同一个人,这意味着,用户 B 可以读取和更改用户 A 的信息,这无疑带来了很大的安全隐患。
黑客攻击的一种方法,就是设法制造“哈希碰撞”,然后入侵系统,窃取信息。
案例二¶
这里举个最常见的例子,我们都用过网络支付工具,假如我们从A帐户转给帐户B 1000块钱,那么在网络传输过程中,有可能被黑客给截持并串改我们的数据,将目标帐户改成黑客自己的帐户。那如何有效地避免这种情况呢。
使用哈希算法,可以在客户端处进转账的信信息进行处理,处理方法是,将要加密的数据加上一个约定好的公钥一起进行哈希,生成一个信息摘要。假如在网络传输过程中不幸被黑客修改了目标帐户,等到了支付平台的服务器端,会将传输过来的信息和之前约定好的公钥再次进行哈希。然后和之前那个哈希进行比对,由于之前的数据已经被串改了,所以验证会失败。从而保证了我们的资金安全。
5.3.2 哈希破解¶
前面讲到了许多哈希在实际生活中的应用,可以发现,哈希大多应用的安全领域。那哈希真的没有办法破解吗?
当然是有,不过破解哈希,是一种体力活。
暴力枚举¶
暴力枚举法,就是简单粗暴的枚举出所有的原文,并计算其哈希值,然后将计算结果与目标哈希值一一比对。由于原文的可能性有无数多种,所以这种方法时间复杂度高得离奇,极不可取。需要大量的计算,因此破解速度非常慢,以14位字母和数字的组合密码为例,共有1.24×10^25种可能,即使电脑每秒钟能进行10亿次运算,也需要4亿年才能破解。
就算有一天,真找到一个和目标哈希值相等的原文,这个原文也不一定是答案,因为哈希冲突的存在,多个原文是有可能有着同一个哈希值。
字典法¶
反思暴力枚举法,它其实做了太多无用的计算。一般人的密码都会取一些有特殊意义的字符,比如生日,名字缩写等。有人就会把这些常用的高频率的密码组合,试先计算并存储起来。等到要用的时候,直接到数据库里查询对应的哈希值就行了。
如果说暴力枚举法,是时间换空间,那字典法就是空间换时间。
需要海量的磁盘空间来储存数据,仍以14位字母和数字的组合密码为例,生成的密码32位哈希串的对照表将占用2.64 * 10^14 TB
的存储空间。如何增加密码长度或添加符号,需要的时间或磁盘空间将更加难以想象,显然这两种方法是难以让人满意的。
(62^14*192)/8/1024/1024/1024/1024=2.64 * 10^14 (TB)
彩虹表法¶
暴力枚举和字典法,都只适用于长度较短,组合简单的密码。
接下来为大家介绍一种高效的密码攻击方法:彩虹表。它可以用于复杂一点的密码。
彩虹表实质上还是属于字典破解的一种,不过不再是简单的明文—密码的对应,为了节省字典存储空间,彩虹表省去了能通过计算得出的数据,达到这点的关键在于设计出一个函数族Rk(k=1、2、3、4……)将hash密文空间映射回明文的字符空间。
具体内容可点击查看:https://mp.weixin.qq.com/s/fLwwu9Ol21SfMRBzA_OyQg
彩虹表的存储空间是字典法的 k 分之一,代价是运算次数至少是原来的 k 倍。
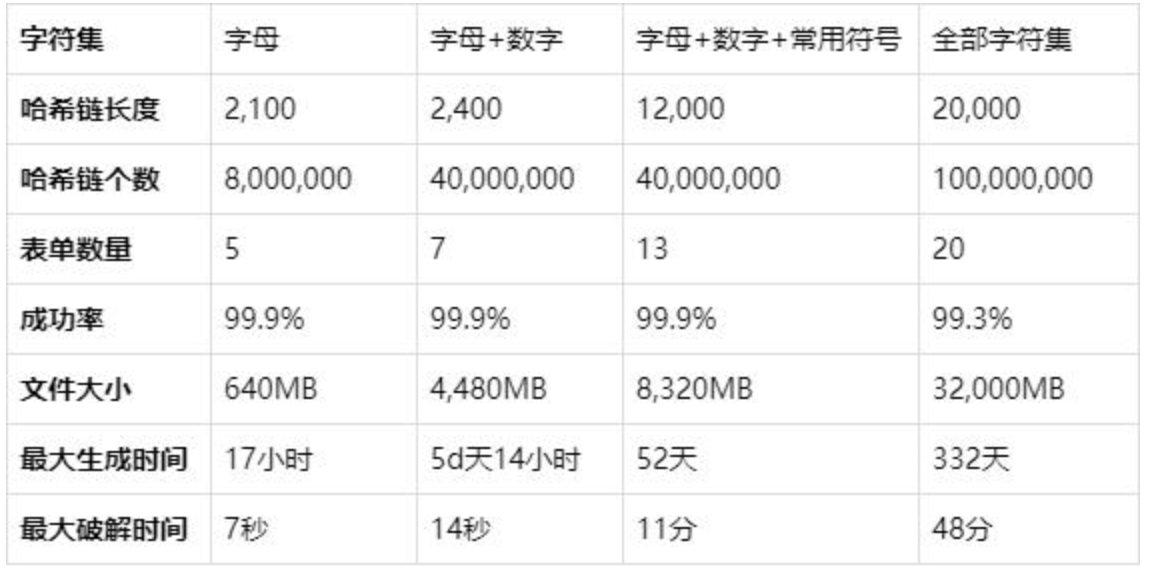
彩虹表确实像它的名字一样美好,至少黑客眼里是这样。下表是7位以内密码在不同字符集下构造出的彩虹表的情况,彩虹表中哈希链的长度和个数随着字符集的增长而增长,彩虹表的大小和生成时间也随之成倍增加。7位数字组合在彩虹表面前简直就是秒破,即使最复杂的7位密码不到一个小时就能破解,如果采用普通的暴力攻击,破解时间可能需要三周。
32位的16进制,我们可以计算一下,可以表示多少原值呢?
通过计算可得:340282366920938463463374607431768211456 个值。
由于哈希算法的定义域是一个无限集合,而值域是一个有限集合,将无限集合映射到有限集合,理论上来讲,产生哈希碰撞是无法避免的。你看md5算法的值域那么大,我们都不能保证其不会产生重复的哈希碰撞。
哈希碰撞是概率事件,只要我们的值域给的够大(能够满足我们的业务需求),产生哈希碰撞的概率就可以很小。但是这个值域也不可能过大,太大了,哈希的计算过程将会变得无法接受,所以工程师需要在二者之间(安全与成本)做一个权衡。
权衡这个东西比较抽象,更多时候,我们需要一个行之有效的计算方法来辅助我们做判断。简单点说,如何计算这个概率值呢?
假设现在有一家公司,它的 API 每秒会收到100万个请求,每个请求都会生成一个哈希值,假定这个 API 会使用10年。那么,大约一共会计算300万亿次哈希。能够接受的哈希碰撞概率是1000亿分之一(即每天发生一次哈希碰撞),请问哈希字符串最少需要多少个字符?
在下面我给你准备了一个函数,你可以通过它来计算
如果我们选定的哈希算法产生的值是32位的二进制数,那么它可以表示4294967296个数。那么重复的概率为一万万亿分之一。
而如果我们选定的哈希算法产生的值是16位的二进制数,那么它可以表示65536个数,那么重复的概率大概在两亿分之一。
from numpy import exp
def calc(d, n):
x = (-n*(n-1))/(2*float(d))
return 1 - exp(x)
print(calc(365, 23)) # 0.500001752183
# d 表示值域
# n 表示定义域
