5.1 图解九大经典排序算法¶

排序算法,可谓是算法中的基础,在面试中,也是面试官最喜欢考察的。经常会让你手写一个选择排序、冒泡排序,如果能在最短的时间内顺畅地写出来,一定会让面试官眼前一亮。
这次我准备以这篇文章,以最通俗简短的语言,配上最直观的排序图解,最后附带优雅的Python代码,一步一步带你入门排序算法。
最后一篇文章,会给大家放个大招,以一个视频的方式,来直观对比下各大排序算法的执行效率。大家敬请期待。
5.1.1 快速排序¶
时间复杂度:O(nlog_2(n)) 空间复杂度:O(log2n) ~ O(n))
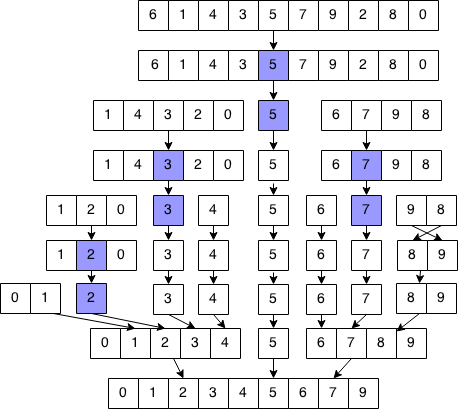
排序原理 :选取一个数组中的某个数,将整个数组分为两个子数组(小于此数的为一组,大于此数的为一组)。然后对分出的子数组,重复以上步骤。
原理图解:
代码实现:
def quick_sort(array, reverse=False):
if len(array) > 0:
pivot = array[0]
# 这里使用列表生成式,是为了代码可读性。
# 这里其实应该使用的是for循环,不然每递归一次就多循环了一次。
less = [x for x in array if x < pivot]
greater = [x for x in array if x > pivot]
# 正序
if not reverse:
return quick_sort(less, reverse) + [pivot] + quick_sort(greater, reverse)
# 倒序
else:
return quick_sort(greater, reverse) + [pivot] + quick_sort(less, reverse)
return []
5.1.2 冒泡排序¶
时间复杂度:O(n^2) 空间复杂度:O(1)
排序原理 :对相邻的元素进行两两比较,顺序相反则进行交换,这样,每一趟会将最小或最大的元素“浮”到顶端,最终达到完全有序。
原理图解 : |\|冒泡排序\||
代码实现:
def bubble_sort(array, reverse=False):
length = len(array)
# 循环length次,每一次都选出一个最大/小值,浮到最后。
for i in range(length):
end = length-i
for k in range(end):
# 正序
if not reverse:
if k+1 < end and array[k] > array[k+1]:
array[k+1],array[k] = array[k],array[k+1]
# 倒序
else:
if k+1 < end and array[k] < array[k+1]:
array[k+1],array[k] = array[k],array[k+1]
return array
5.1.3 选择排序¶
时间复杂度:O(n^2) 空间复杂度:O(1)
排序原理 :遍历n趟(n为数组的长度),每一趟都从「待排序」的元素中排出最小(或最大)的元素。
原理图解 :

代码实现:
def select_sort(array, reverse=False):
length = len(array)
for x in range(length):
# 每次循环里,最大或者最小值的索引:边缘索引
edge_index = 0
for y in range(length-x):
# 正序
if not reverse:
if array[y] > array[edge_index]:
edge_index = y
# 倒序
else:
if array[y] < array[edge_index]:
edge_index = y
array[length-x-1],array[edge_index] = array[edge_index],array[length-x-1]
return array
5.1.4 插入排序¶
时间复杂度:O(n^2) 空间复杂度:O(1)
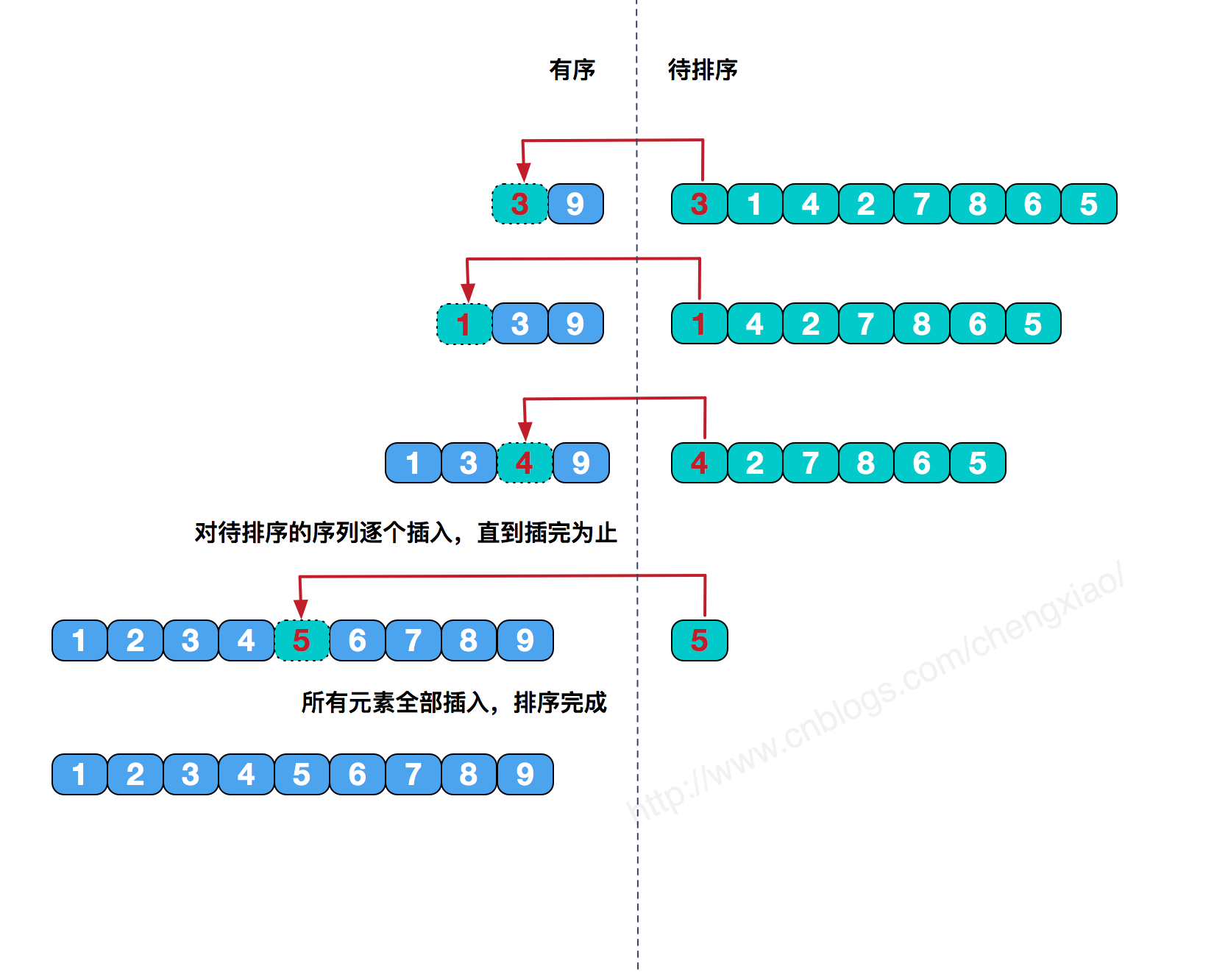
排序原理 :每次将一个待排序的元素与已排序的元素进行逐一比较,直到找到合适的位置按大小插入。通俗地说,就类似我们打牌的时候,给牌进行排序。
原理图解 :
代码实现:
def insert_sort(array,reverse=False):
length = len(array)
for index in range(1,length):
# 当前要比较的值
current_value = array[index]
position = index
# 正序
if not reverse:
while position>0 and array[position-1]>current_value:
array[position] = array[position-1]
position -= 1
array[position] = current_value
# 倒序
else:
while position>0 and array[position-1]<current_value:
array[position] = array[position-1]
position -= 1
array[position] = current_value
return array
附:网上看到一种简洁的写法,但是由于内部使用了insert函数,效率其实并不高,可以做为理解使用。这代码只是正序的哦。
def insert_sort(array):
for i in range(len(array)):
for j in range(i):
if array[i] < array[j]:
array.insert(j, array.pop(i))
break
return array
5.1.5 希尔排序¶
时间复杂度:\(O(nlogn)\) ~ \(O(n^2)\) 空间复杂度:\(O(1)\)
排序思想: 希尔排序,有时也叫做“最小增量排序”,该算法是冲破\(O(n^2)\)的第一批算法之一。通过把原始的序列以增量(网上通常叫做gap,意为间隔,在下面代码中我把它体现为分组数,group_num。)进行分组,分解成几个子序列来提高效率,其中每个小序列使用的都是插入排序,使得该组有序。
原理图解:
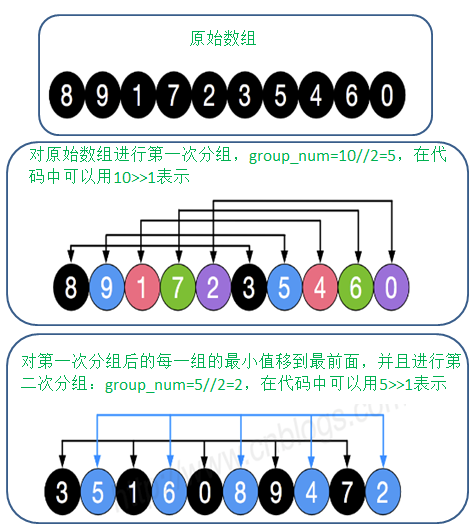
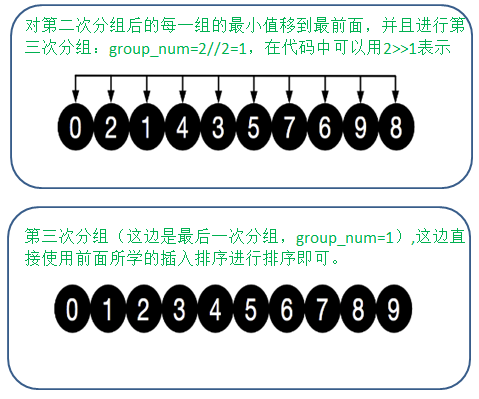
代码实现:
def shell_sort(array, reverse=False):
length = len(array)
# 长度的一半,>> 是位运算,相当于是"length//2"
group_num = length >> 1
while group_num > 0:
for i in range(group_num, length):
current_index_value = array[i]
# k的作用:用于当前索引往前移动n个group_num的索引
k = i
# while循环把同一组的最小值移到最前
# 正序
if not reverse:
while k >= group_num and array[k-group_num] > current_index_value:
array[k] = array[k-group_num]
# 索引往前移动
k -= group_num
# 倒序
else:
while k >= group_num and array[k-group_num] < current_index_value:
array[k] = array[k-group_num]
# 索引往前移动
k -= group_num
array[k] = current_index_value
group_num >>= 1
return array
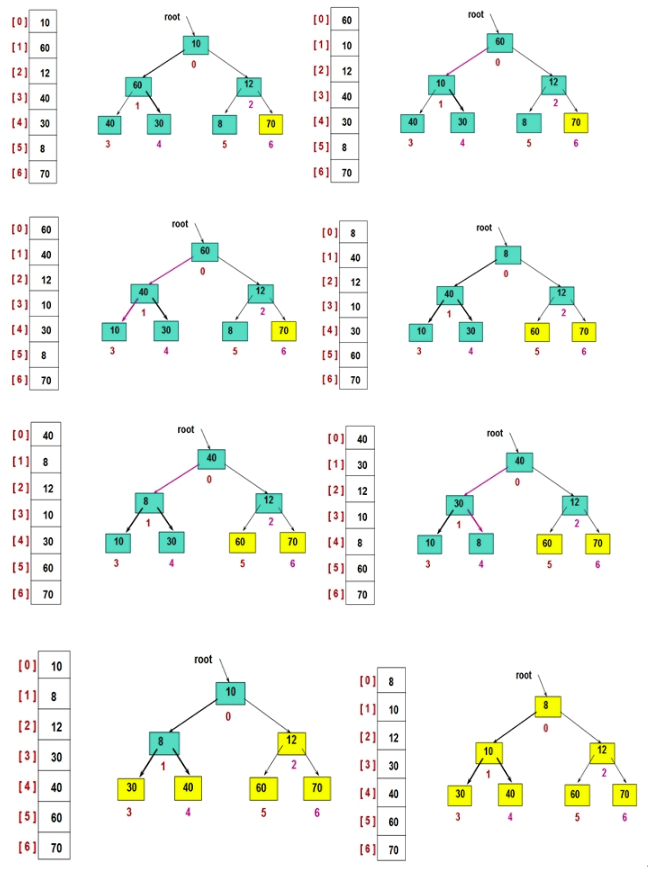
5.1.6 堆排序¶
时间复杂度:\(O(nlogn)\) 空间复杂度:\(O(1)\)
要掌握堆排序,有一些预备知识,你需要了解,你必须得知道,什么是堆(二叉堆),什么是最大堆,什么是最小堆?
我在网上找了一篇很好教程,有需要可以前往查阅:http://blog.51cto.com/jx610/1702260
排序思想:堆排序,如果是正序,就把最大堆堆顶的最大数取出,将剩余的堆继续调整为最大堆,再次将堆顶的最大数取出,这个过程持续到剩余数只有一个时结束。如果是倒序,就把最小堆堆顶的最小数取出,将剩余的堆继续调整为最小堆,再次将堆顶的最小数取出,这个过程持续到剩余数只有一个时结束。
其实难点,在于如何在剩余堆里,找到最大数(或者最小数)。
原理图解:
代码实现:
由于这里代码较多,为了不增加理解难度,先只实现了正序。
# 建立最大堆
def build_max_heap(arr, start, end):
root = start
while True:
# 从root开始对最大堆调整
child = 2 * root + 1
# 避免和已排过的数再比较
if child > end:
break
# 找出两个child中较大的一个
if child + 1 <= end and arr[child] < arr[child + 1]:
child += 1
if arr[root] < arr[child]:
# 最大堆小于较大的child, 交换顺序
arr[root], arr[child] = arr[child], arr[root]
# 正在调整的节点设置为root
root = child
else:
# 无需调整的时候, 退出
break
def heap_sort(arr):
# 从最后一个有子节点的节点开始,调整最大堆
first = len(arr) // 2 - 1
for start in range(first, -1, -1):
build_max_heap(arr, start, len(arr) - 1)
# 将最大的放到堆的最后一个, 堆-1, 继续调整排序
for end in range(len(arr) -1, 0, -1):
arr[0], arr[end] = arr[end], arr[0]
build_max_heap(arr, 0, end - 1)
return arr
同理,倒序也是一样,只要实现建立小堆函数即可。
def build_min_heap(arr, start, end):
root = start
while True:
# 从root开始对最小堆调整
child = 2 * root + 1
# 避免和已排过的数再比较
if child > end:
break
# 找出两个child中较小的一个
if child + 1 <= end and arr[child] > arr[child + 1]:
child += 1
if arr[root] > arr[child]:
# 最大堆小于较小的child, 交换顺序
arr[root], arr[child] = arr[child], arr[root]
# 正在调整的节点设置为root
root = child
else:
# 无需调整的时候, 退出
break
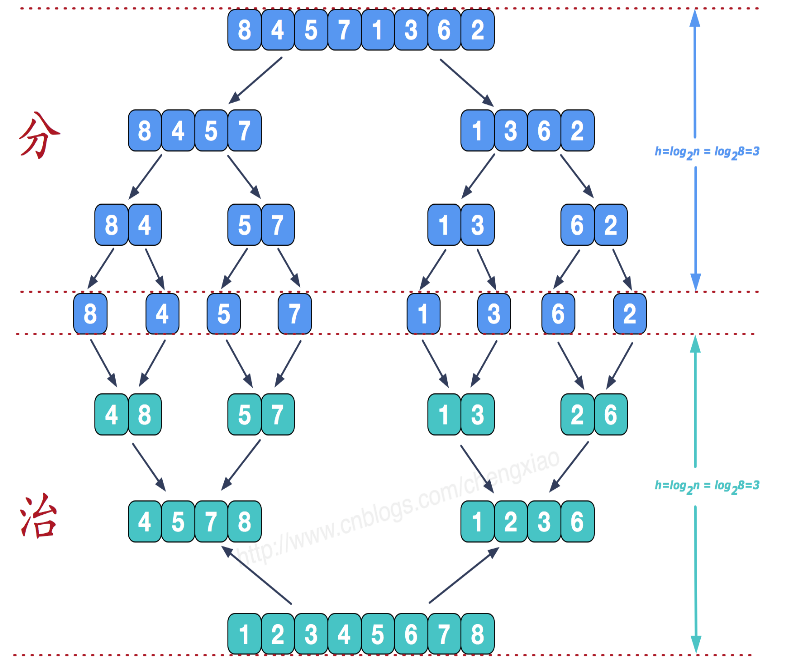
5.1.7 归并排序¶
时间复杂度:\(O(nlogn)\) 空间复杂度:\(O(1)\)
排序思想:归并排序,是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案“修补”在一起,即分而治之)。
第一次接触到这个分治思想,是在《算法图解》这本书里,里面举的一个「分割土地」的例子非常生动形象。精髓就是,不断将问题的规模缩小化,然后逐步往上解决问题。
原理图解:
重点其实是这个“治”的过程,如何实现将两个有序数组合并起来?思路大概是这样的。
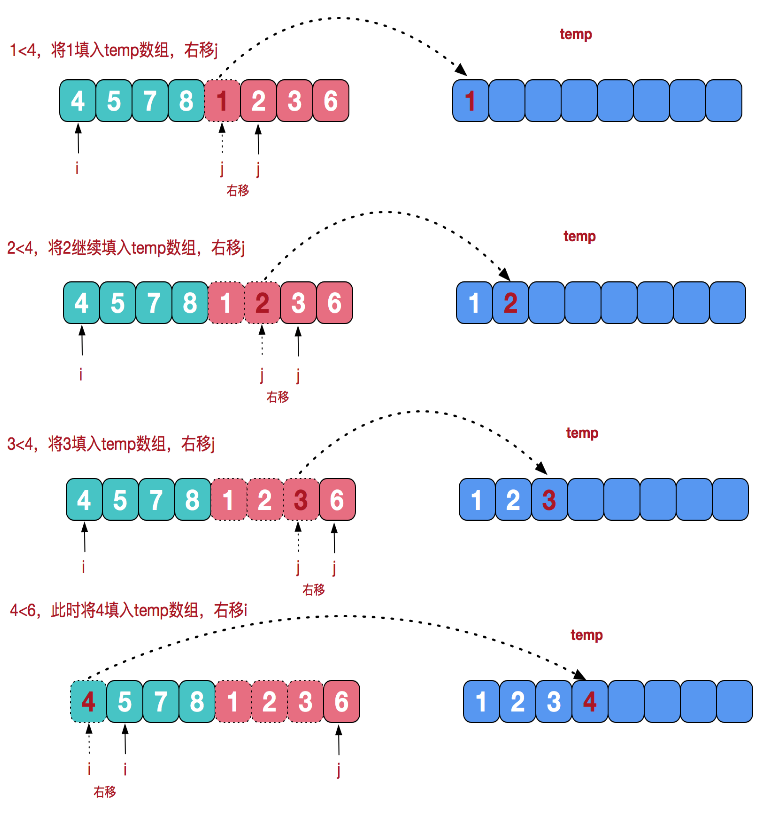
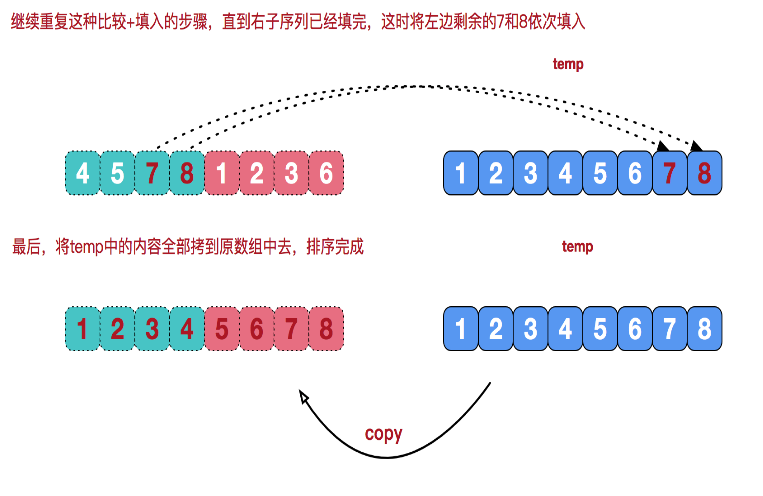
代码实现: 这里只实现正序,感兴趣的同学,可以试倒序。
# 分:分割最小化数组
def merge_sort(seq):
if len(seq) <= 1:
return seq
mid = int(len(seq) / 2)
left = merge_sort(seq[:mid])
right = merge_sort(seq[mid:])
return merge(left, right)
# 治:合并两有序数组
def merge(left, right):
result = []
i, j = 0, 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
return result
5.1.8 桶排序¶
时间复杂度:\(O(N+N*logN-N*logM)\),桶的个数为M,N为元素个数 空间复杂度:\(O(N+M)\)
排序思想:桶排序(或所谓的箱排序),工作的原理是将数组分到有限数量的桶里。下面的代码我以每个数为一个桶,比较直观。可是你要知道当数组范围比较大时,可以以一个范围为一个桶(比如1-100一个桶,102-200一个桶),然后在桶内再使用别的排序算法或者以递归方式继续使用桶排序进行排序。
桶排序是有局限性的,一般情况下,他并不能对有负数或者有小数的数组进行排序。另一方面,在无法预知数组的真实情况下,其实排序性能是非常不稳定的。比如,你可能遇到这样一个数组[1,4,5,1000000],按照桶算法以下面的代码运行,你需要1000000个桶,非常慢,而实际上,这个数组很小,使用任意比较排序算法很快就能结果。
原理图解:
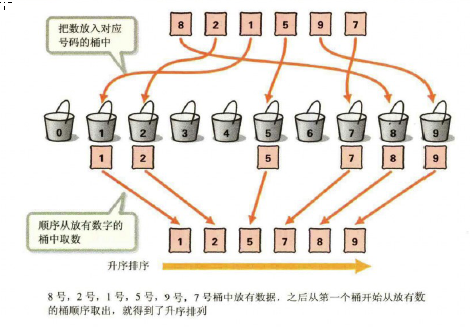
代码实现:
def bucket_sort(array, reverse=False):
_max = max(array)
_min = min(array)
# 桶的个数
buckets = [0] * (_max - _min + 1)
# 在桶里记录每个数出现的频率
for i in array:
buckets[i-_min] += 1
sorted_list = []
for index, item in enumerate(buckets):
if item != 0:
# 重复的数值要存储多次
for x in range(item):
sorted_list.append(index+_min)
# 正序
if not reverse:
return sorted_list
# 倒序
else:
return sorted_list[::-1]
5.1.9基数排序¶
时间复杂度:\(O(log_RB)\) ,B是真数(0-9),R是基数(个十百) 空间复杂度:\(O(n)\)
排序思想:是一种非比较型整数排序算法。其排序原理是,将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位(个位)开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序法会使用到桶 (Bucket),顾名思义,通过将要比较的位(个位、十位、百位…),将要排序的元素分配至 0~9 个桶中,借以达到排序的作用,在某些时候,基数排序法的效率高于其它的比较性排序法。
基数排序的方式可以采用 LSD (Least sgnificant digital) 或 MSD (Most sgnificant digital),LSD 的排序方式由键值的最右边开始,而 MSD 则相反,由键值的最左边开始。
根据每位上的数值进行排序时,都会有以下两步: -
分配。首先要将待排序序列中的当前位上的数字找到对应的桶; -
收集。分配后需要对桶中的记录再串起来,形成一个新的排序序列,供下一次分配用。
直至遍历完成,得到排序好的序列。
如何实现正序和倒序?
顺序的区别,其实就是你收集的时候,也就是将桶的元素串起来的时候,如果你是先从小号桶串起,那就是正序,如果你是从大号桶串起,那就是倒序。
原理图解:
这里图解下,正序的过程。 原始数组:22, 33, 43, 55, 14, 28, 65, 39, 81,
33, 100
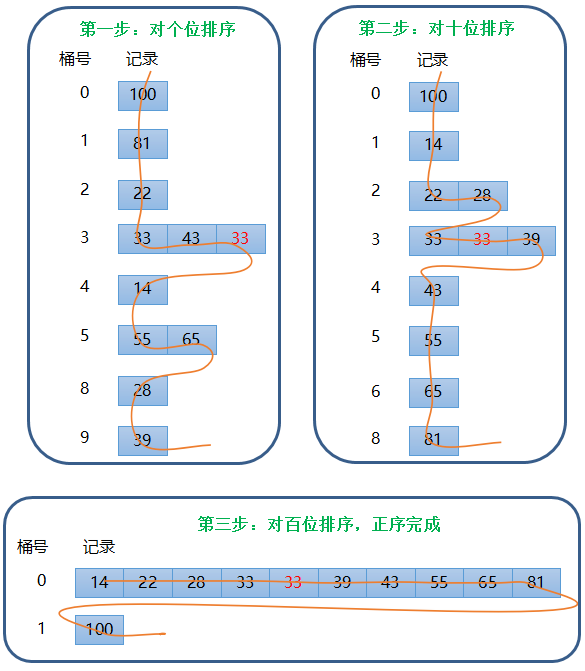
代码实现:
def radix_sort(array, reverse=False):
# 最大的数有几位,决定了要几轮排序
d = len(str(max(array)))
for k in range(d):
# 因为每一位数字都是0~9,故建立10个桶
buckets=[[] for i in range(10)]
for i in array:
# 举例:132//10=13,13%10=3
buckets[i//(10**k)%10].append(i)
array=[item for items in buckets for item in items]
if not reverse:
return array
return array[::-1]
