1.12 搞懂字符编码的前世今生¶

初学计算机的人,肯定对众多字符编码感到头疼。为什么会那么多字符串编码? 这些内容是在去年整理的,现在重新整理下,发布在博客,搞懂字符串编码,这一篇文章足矣
1. 前言必知¶
初学计算机的人,肯定对众多字符编码感到头疼。为什么会那么多字符串编码?
这些内容是在去年整理的,现在重新整理下,发布在博客,方便查看。
bit,位,一个bit可以表示两个数字,0和1 byte,字节,一个byte由8个bit表示,一个byte表示的数字区间[0,255]
2. ASCII编码¶
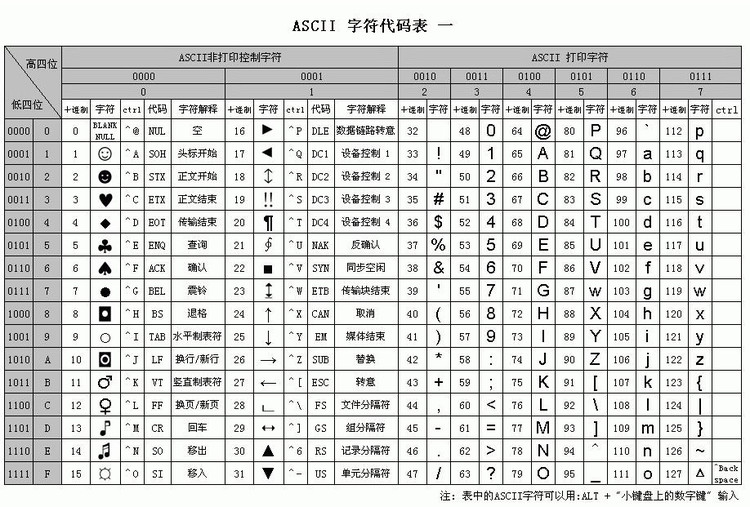
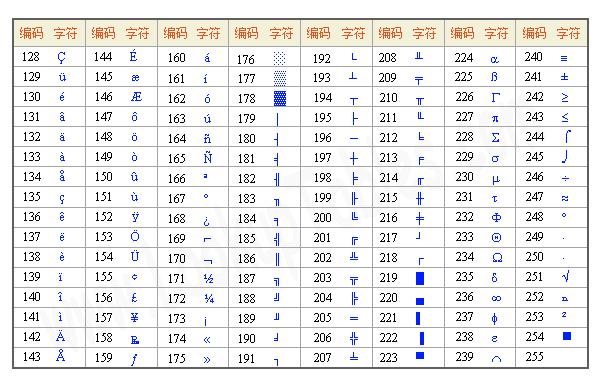
3. ANSI标准¶
ANSI:美国国家标准学会(AMERICAN NATIONAL STANDARDS INSTITUTE)
随着计算机的全世界普及,世界各国都用的上计算机了。但是每个国家都有各自的语言,而传统的计算机只支持ASCII编码表的字符。这对于不以英语为母语的人来说,使用计算机是非常吃力的。为了解决这个问题,各个国家的人都出了一套收录自己文字的字符编码(当然包含了ASCII里所有字符)。
中国大陆编写了GB2312,中国台湾编写了Big5,日本编写了Shift_JIS…
好了,这下各国国人都能看懂计算机的语言了。
需要特别说明的是,ANSI不是一个编码(需要在特定系统中ANSI编码才有意义),而是一种标准。
在英文Windows中,ANSI编码是
ASCII编码在简体中文Windows中,ANSI编码是
GB2312在繁体中文Windows中,ANSI编码是
Big5在日文Windows中,ANSI编码是
Shift_JIS…
4. Unicode编码¶
上节讲到各国都有了自己的编码,已经可以正常使用电脑了。 但是随着国际交流的日益频繁和迫切需要,我们中国人也要和美国人进行信息交流,美国人还要和日本人进行信息交流。假设,我们把一篇中文论文发到网上,美国人在用自己的计算机查看这个网页的时候,由于本地计算机不支持GB2312,结果无法显示正确信息,或者乱码。你会说,那很简单啊,让美国人在电脑上装上GB2312编码不就OK。真的OK吗?世界上那么多国家,那么多语言,那么多ANSI编码,都装上是不是要疯了。好吧,假如你真的不厌其烦的装上了,再假设,有一个中国人,他不仅会说汉语,还会说日语。他发表了一篇既有汉语也有日文的文章,而美国人在看这篇文章的时候,是用GB2312来解码呢,还是用Shift_JIS来解码呢?无论用哪个解码都会出现乱码的情况。
至此,编码的问题还未解决~
这个时候,Unicode编码就站了出来,将全世界的字符统一编码到一起。每个字符都有对应的位,再也不会有乱码发生了,只要你的电脑支持Unicode编码。
Unicode是由统一码联盟(英语:The Unicode Consortium),一个统筹统一码(Unicode)发展的非营利机构,其宗旨为最终以统一码取代现存的字符编码,因为现存编码不能够在多语言电脑环境中使用,而且字符数有局限。
Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2017年6月20日公布的10.0.0,已经收入超过十万个字符(第十万个字符在2005年获采纳)。Unicode-维基百科
5. UTF-8编码¶
Unicode,通常是由两个字节表示一个字符,特殊情况下,四个字节表示一个字符。 ASCII,一个英文字符由一个字节表示。 我们假设,美国人写了一篇纯英文的文章,存储在本地,本来用ASCII编码到时候,只要10kb的容量,而用Unicode编码,却用了20kb。当我们的数据越来越多的时候,存储空间的浪费是成倍的。这明显是非常不合理的。
不要捉急,万事都是有解决方法的。 UTF-8(UTF:Unicode TransferFormat,即把Unicode转做某种格式的意思)应运而生 用UTF-8编码,英文字符还是用一个byte表示,汉字用两个字节或三个字节(生僻字)表示。
这下好了,两全其美。既能使计算机适应多语环境,又解决了传输速度和存储浪费的问题。
扩展问题
UTF-8有用一个字节表示,有用两个字节表示,读取数据,如何识别是几个字节表示一个字符?

‘联通’显示乱码 当在txt输入输入’联通’,保存再次打开就乱码,输入’你好联通’就不会出现这个情况。

6. 编码之于Python¶
Python2 Python2默认是使用ASCII编码,这也是出现编码问题的罪魁祸首。但这也不怪Python,在Python诞生的时候,Unicode还没出现。 所以在Python2中,可以用如下方式进行字符串编码的转换
--- 编码 ---
u'ABC'.encode('utf-8')
# 'ABC'
u'中文'.encode('utf-8')
# '\xe4\xb8\xad\xe6\x96\x87'
#\xe4 表示一个字节
--- 解码 ---
'abc'.decode('utf-8')
# u'abc'
'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
# u'\u4e2d\u6587'
print '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
中文
Python3
在Python3中,已经默认使用Unicode编码了。解决了很多编码的问题。
如果py文件中,含有中文还是得在文件头出加入 # coding=utf-8
7. 扩展阅读¶
中文编码的发展 GB2312-> GBK -> GB18030
GBK GBK,全称《汉字内码扩展规范》 由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订。 对GB2312进行扩展(K就是扩展的意思),增加繁体中文,日文韩文 共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。
GB18030 GB 18030,全称:国家标准 GB 18030-2005《信息技术中文编码字符集》 是中华人民共和国现时最新的内码字集,是 GB 18030-2000《信息技术信息交换用汉字编码字符集基本集的扩充》的修订版。 GB 18030 与 GB 2312-1980 和 GBK 兼容,共收录汉字70244个。
